
Update, 1 July 2026: a month on, they arrived
When this went out, our 11-day log showed only Meta and Bing. A month on, the picture changed: over the 30 days to 29 June, 11 AI crawlers made 73 requests to this site's files, none blocked, and the major LLM crawlers were among them this time. Nine of the ten files were read. The full breakdown with screenshots is in our Q3 2026 adoption report; the bot-by-bot record is in the update log below.
The claim: AI crawlers ignore these files
If you've read anything sceptical about llms.txt in the last year, it probably said some version of this: nice idea, but the AI crawlers don't actually read it. The evidence behind that claim is real and worth taking seriously.
OtterlyAI ran a 90-day experiment and found that out of more than 62,100 AI bot visits to their test site, just 84 touched /llms.txt. That's roughly 0.1%. Their conclusion was blunt: AI agents are discovering content through normal pages and site structure, not through llms.txt. Separately, Flavio Longato audited 30 days of CDN logs across 1,000 Adobe Experience Manager domains and reported seeing no GPTBot, ClaudeBot, or PerplexityBot on the file at all. Googlebot accounted for nearly 95% of the requests that did arrive.
Then there's the line that started a lot of the arguments.
"AFAIK none of the AI services have said they're using llms.txt (and you can tell when you look at your server logs that they don't even check for it). To me, it's comparable to the keywords meta tag."
John Mueller, Google Search Advocate, in a Reddit discussion reported by Search Engine Journal (verify quote at source)
I've quoted Mueller approvingly plenty of times, so reading this stung a little. He's pointing at the one piece of evidence I'd usually reach for to settle an argument: the server logs. Not a survey, not a vendor's dashboard, the raw record of what actually hit the server. So when we put our own WordPress plugin on a real site and switched on crawler logging, his line is exactly the thing I was bracing to confirm. I half-expected the logs to be empty. They weren't.

What we measured, and how
Just over a week before writing this, we installed the AI Discovery Files plugin on mcneece.com, a personal WordPress site of mine. The plugin publishes all ten files from the AI Discovery Files specification and, with logging enabled, records every request an AI crawler makes to one of them: which bot, which file, the HTTP status, and the timestamp.
This is the cleanest kind of evidence there is. It isn't a third-party tool simulating requests, and it isn't analytics that filter bots out before you ever see them. It's the server writing down what reached it. The catch with server logs is that they only show what happened on that one site, so I'm not claiming these 11 days describe the whole web. I'm claiming they describe this site, exactly, with no interpretation in between.
A few things about the setup matter for reading the numbers. The site is small and new to these files. It had no inbound links pointing at the discovery files, no campaign driving traffic, and the plugin serves each file with a short cache life so requests reach PHP and get logged rather than being absorbed by a CDN edge. Logging only counts bots from a known registry of AI and search crawlers, matched on user-agent. Ordinary human visits and generic scrapers aren't in here. What follows is AI and search crawlers only.
The log: 11 days, 15 crawler hits
Between 22 May and 1 June 2026, the files were crawled 15 times, by two named operators, on 10 of the 11 days. Every single request returned a 200. Here's the headline split.
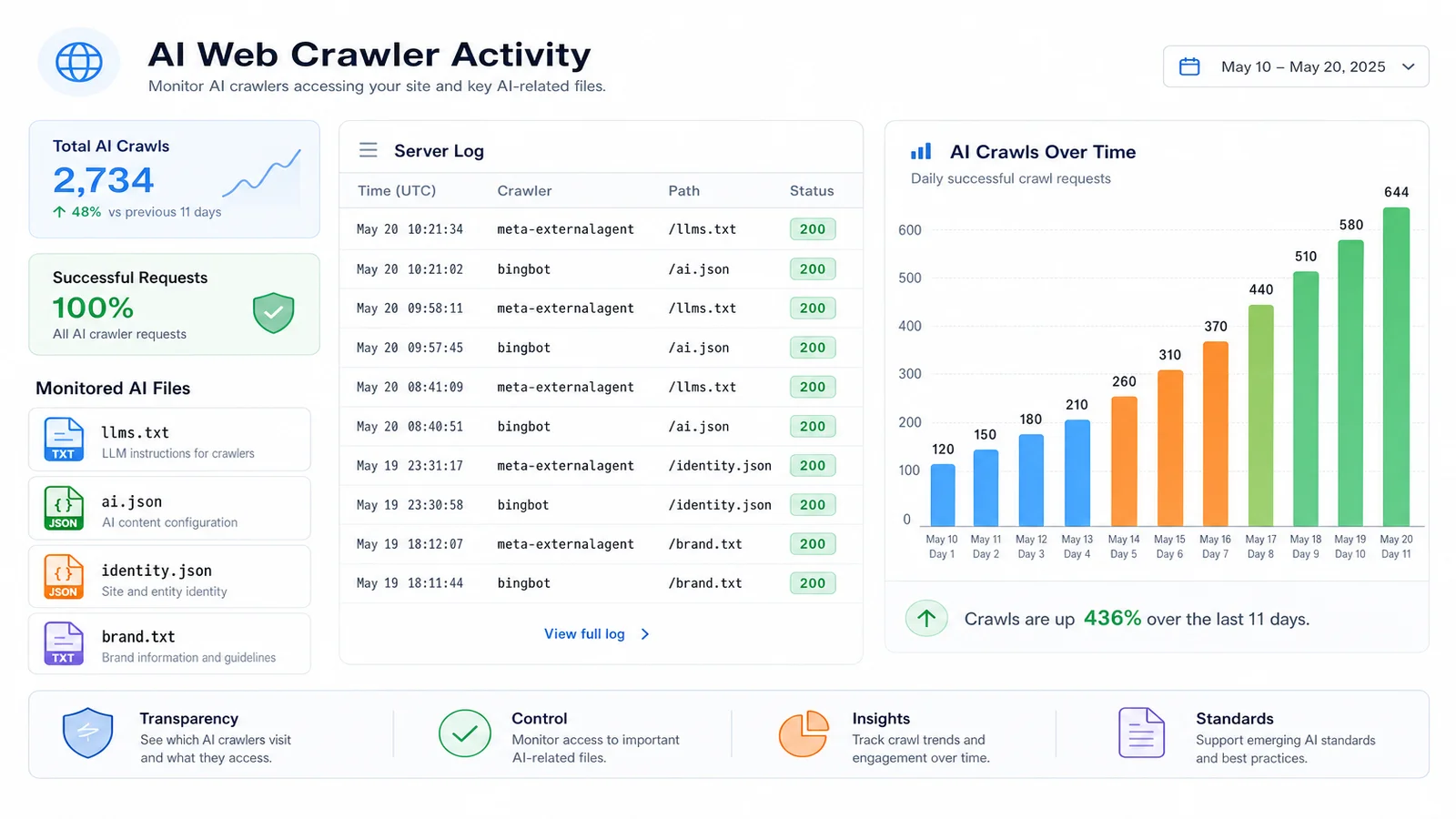
| Crawler | Operator | Hits | Files touched |
|---|---|---|---|
meta-externalagent | Meta | 12 | 7 different files |
bingbot | Microsoft | 3 | 2 (both JSON) |
| Total | 2 operators | 15 | 8 of 10 files |
Eight of the ten files were fetched at least once. The two that weren't, in this window, were llm.txt (the singular alias of llms.txt) and developer-ai.txt. Here's the per-file breakdown.
| File | Hits | Crawled by |
|---|---|---|
/llms.txt | 3 | Meta |
/ai.json | 3 | Meta, Bing |
/brand.txt | 2 | Meta |
/faq-ai.txt | 2 | Meta |
/robots-ai.txt | 2 | Meta |
/llms.html | 1 | Meta |
/ai.txt | 1 | Meta |
/identity.json | 1 | Bing |
And the daily cadence, because "every day" is the part that surprised me most. One bot or two, almost without a gap.
| Date | Hits | Activity |
|---|---|---|
| 22 May | 2 | Bing |
| 23 May | 1 | Meta |
| 24 May | 1 | Meta |
| 25 May | 3 | Meta, Bing |
| 26 May | 0 | quiet |
| 27 May | 1 | Meta |
| 28 May | 1 | Meta |
| 29 May | 1 | Meta |
| 30 May | 1 | Meta |
| 31 May | 2 | Meta |
| 1 Jun | 2 | Meta |
One quiet day in eleven. For a site that nobody is linking to and nobody is searching for, that's a crawler showing up to read machine-readable files it has no traffic-based reason to want. If you'd told me beforehand the logs would be empty, I'd have believed you. They aren't empty. They're a steady drip.
Here's the full raw log, every row, so you can check my arithmetic. This is the export straight out of the plugin, timestamps in UTC.
| Time (UTC) | Crawler | File | Status |
|---|---|---|---|
| 2026-06-01 09:42 | meta-externalagent | /llms.txt | 200 |
| 2026-06-01 08:51 | meta-externalagent | /brand.txt | 200 |
| 2026-05-31 07:06 | meta-externalagent | /llms.html | 200 |
| 2026-05-31 01:48 | meta-externalagent | /llms.txt | 200 |
| 2026-05-30 01:30 | meta-externalagent | /ai.txt | 200 |
| 2026-05-29 18:44 | meta-externalagent | /faq-ai.txt | 200 |
| 2026-05-28 11:16 | meta-externalagent | /llms.txt | 200 |
| 2026-05-27 17:08 | meta-externalagent | /robots-ai.txt | 200 |
| 2026-05-25 17:14 | meta-externalagent | /ai.json | 200 |
| 2026-05-25 11:11 | bingbot | /ai.json | 200 |
| 2026-05-25 02:32 | meta-externalagent | /faq-ai.txt | 200 |
| 2026-05-24 12:47 | meta-externalagent | /robots-ai.txt | 200 |
| 2026-05-23 10:03 | meta-externalagent | /brand.txt | 200 |
| 2026-05-22 12:59 | bingbot | /ai.json | 200 |
| 2026-05-22 12:59 | bingbot | /identity.json | 200 |
What Meta and Microsoft each went for
The two crawlers behaved completely differently, and the difference is the most interesting thing in the data.
Meta read almost the whole set
meta-externalagent is Meta's crawler. It launched in mid-2024 to collect public web content for training the Llama models and powering Meta AI across Facebook, Instagram, WhatsApp, and Threads. Over the 11 days it didn't just glance at one file and leave. It worked through the set: llms.txt three times, then brand.txt, faq-ai.txt, robots-ai.txt, llms.html, ai.txt, and ai.json. Seven different files, returning across the fortnight to pick up more of them.
That pattern is hard to square with "bots ignore these files". A crawler that's indifferent fetches robots.txt and moves on. A crawler that comes back for brand.txt (naming and terminology rules) and faq-ai.txt (questions with verified answers) is reading the things that only exist to describe an entity to a machine.

Bing went straight for the structured identity
bingbot is Microsoft's search crawler, and its index feeds Microsoft Copilot. It made three requests, and it ignored every plain-text file. It fetched ai.json twice and identity.json once, and nothing else. Those are the two files in the spec that carry structured, machine-parseable identity: the permissions record and the formal identity record, both JSON.
I find that selectivity quietly persuasive. A crawler that wanted to dismiss these files wouldn't single out the two that are hardest to fake and easiest to parse deterministically. Bing read the structured identity and left the prose alone. That's a vote, in behaviour rather than words, for publishing machine-readable data over hoping a model infers you correctly from your HTML.
The honest caveat: who didn't show up
Now the part that keeps this honest. Four crawlers I'd have loved to see in the log weren't there at all: OpenAI's GPTBot, Anthropic's ClaudeBot, PerplexityBot, and Google-Extended. Not once in 11 days.
If you only read the headline of this post, you might think it disproves the sceptics. It doesn't, and I'm not going to pretend it does. The big dedicated LLM crawlers stayed away from this small, new, link-poor site, which is exactly what OtterlyAI and Longato would predict. Their data isn't wrong. What it misses is that "the LLM bots are quiet" and "nobody reads the files" are two different claims. Meta and Microsoft read them, daily, while the others were absent. Two larger studies have since put hard numbers on that quiet, and we weigh them against this log in our Q3 2026 adoption report.
It's worth knowing those absent crawlers are anything but idle elsewhere. Cloudflare measured how hard they hit the wider web, and the ratios are startling.
"If the Internet is going to survive the age of AI, we need to give publishers the control they deserve and build a new economic model that works for everyone."
Matthew Prince, co-founder and CEO of Cloudflare, in the 1 July 2025 Cloudflare announcement (verify quote at source)
What makes Prince's worry land for me is the number underneath it. In June 2025, Cloudflare found OpenAI's crawler scraped sites about 1,700 times for every referral it sent back, and Anthropic's scraped roughly 73,000 times per referral. These bots are voracious. They just hadn't reached my little site yet, because nothing was pointing them at it. The absence in my log isn't evidence they don't crawl. It's evidence they hadn't found a reason to crawl here, yet. As the site picks up links and starts surfacing in queries, I expect that to change, and I'll update this post when it does.
Why the files get read at all
So why would Meta and Microsoft bother fetching a stack of text and JSON files from a site they've no commercial reason to care about? Because the files answer a question every crawler has and most websites leave ambiguous: who is this, and what are they allowed to do with it?
A normal page makes a machine infer your identity from markup, navigation, and copy written for humans. The AI Discovery Files state it directly. identity.json gives a formal identity record. ai.json and ai.txt declare what's permitted for AI training and AI search. brand.txt fixes the naming so you don't get paraphrased wrong. When a crawler can fetch that in one request and get an unambiguous answer, it's cheaper and safer than guessing. Bing's behaviour, going only for the JSON, is the clearest sign of that logic in action.
This is the same mechanism we documented when a three-week-old locksmith site got recommended by ChatGPT and Gemini ahead of established competitors: see the Lockerfella case study. Machine-readable identity gets read early, before the slow authority signals that traditional SEO depends on have had time to build. If you want the mechanics of how that retrieval works end to end, we walked through it in how AI search actually works.
None of this means a fetch equals a citation. Being crawled is the foundation, not the finish. It means the file was there, it returned cleanly, and a major AI operator took the content. What the operator does with it next is a separate question. But you can't be read correctly by a system you've given nothing clean to read.
Google now puts a number on part of this too. Its Lighthouse engine, behind PageSpeed Insights, scores a valid llms.txt as one of three checks in a new Agentic Browsing category. We broke down what it measures in Agentic Browsing: Google now scores your site for AI agents.
How to check your own site
The advice you'll usually get for this is "analyse your server logs". It's correct, and it's also a chore. You SSH in, pull the access logs, and grep for a list of user-agents you have to keep up to date yourself, then dedupe and count by hand. Most site owners never do it, which is why so many assume nothing is crawling them.
There's a shorter path. If your site runs WordPress, the AI Discovery Files plugin publishes all ten files and logs every AI crawler hit to them, then shows you the same breakdown you've just read: which bots, which files, how often, with a one-click CSV export. The log in this article is that export, untouched. You don't have to take my word for any of it, because the tool hands you your own version of the same evidence.
See which AI crawlers are reading your site
The AI Discovery Files plugin publishes all ten files and logs every AI crawler hit, so you get this exact breakdown for your own domain. Prefer a one-off audit first? The AI Visibility Checker shows which files you have, which you're missing, and whether crawlers are allowed in.
Get the pluginIf you'd rather start with the why before the how, why AI visibility matters sets out the case, and is your website blocking AI? covers the crawler-access mistakes that stop any of this working. Whatever you use to check, check with logs. As Mueller said, they're where the truth is. Mine just told a different story than I expected. For a site that wants to be found by AI, you can also list it in the free AI Visibility Directory, and the team behind all of this is 365i, with the design side at 365i Web Design.
Frequently asked questions
Do AI crawlers actually read llms.txt and other AI Discovery Files?
Yes, some do. On a brand-new site we logged 15 crawler hits across 11 days, all of them from Meta's AI crawler and Microsoft's Bing, reaching 8 of our 10 AI Discovery Files. The headline LLM bots (OpenAI's GPTBot, Anthropic's ClaudeBot, PerplexityBot) did not appear in that short window, so the honest answer is "some crawlers, not all, and it depends which file".
Which AI crawlers visited the files?
Two named operators. meta-externalagent (Meta's crawler, used to train Llama and power Meta AI) accounted for 12 of the 15 hits and worked through nearly the whole file set. bingbot (Microsoft, whose index feeds Copilot) made the other 3 hits and went only for the structured JSON files, ai.json and identity.json.
Didn't Google say AI services don't even check for llms.txt?
Google's John Mueller said you can tell from your server logs that AI services don't check for the file. Our logs are a counter-example: Meta requested llms.txt three times in 11 days. Mueller's wider point still holds for the big LLM bots in this window. The picture is more mixed than either "they all read it" or "nobody reads it".
How can I tell if AI is crawling my own website?
Your server access logs are the only complete record. Filter them for AI user-agents like GPTBot, ClaudeBot, PerplexityBot, meta-externalagent, and bingbot. If you run WordPress, the AI Discovery Files plugin logs every bot hit to your discovery files automatically and shows the breakdown in a dashboard, so you don't have to grep raw logs by hand.
How quickly did the crawlers find a brand-new site?
Fast. The plugin went live just over a week before we pulled the logs, and the first crawler hits landed on day one of the files being published. The site had no backlinks, no Google authority, and barely any index presence. Machine-readable identity got read before traditional authority signals had a chance to accumulate.
Does publishing AI Discovery Files guarantee AI visibility?
No, and we won't pretend it does. Being crawled means a file was fetched and returned a 200, not that an AI will cite you. The files remove ambiguity so that when an AI does read your site, it gets your identity, services, and permissions right. That's a necessary foundation, not a guarantee of a citation. We cover the difference in what Google actually said about llms.txt.
Why did Bing only fetch the JSON files?
We can't see inside Microsoft's crawler, but the pattern is telling: bingbot went straight for ai.json and identity.json, the two structured, machine-parseable identity files, and ignored the plain-text ones. Structured data is easier to ingest deterministically, which is the whole argument for publishing it.
Will GPTBot and ClaudeBot crawl the files eventually?
Probably, as the site gains links and surfaces in queries. Cloudflare's data shows OpenAI and Anthropic crawl the wider web aggressively, just not yet on a tiny new domain with no signals pointing to it. We'll update this post with the 30 and 90-day figures to show how the crawler mix changes as the site matures.
Sources
- mcneece.com llms.txt (the live file in the log)
- AI Discovery Files plugin (the tool that logged the data)
- Google Says LLMs.txt Comparable To Keywords Meta Tag - Search Engine Journal
- The llms.txt Experiment (90-day study) - Otterly AI
- llms.txt CDN log audit across 1,000 domains - Flavio Longato
- Cloudflare changes how AI crawlers scrape the Internet - Cloudflare (Matthew Prince)
- Crawl-to-referral ratios for Google, OpenAI and Anthropic - TechCrunch
- Meta web crawlers documentation (meta-externalagent) - Meta for Developers