
The headline
This is our third quarterly crawl of AI Discovery File adoption, and for the third quarter running, the numbers went up.
Adoption of AI Discovery Files rose from 7.2% to 9.4% of top websites. llms.txt, the file almost everyone starts with, climbed from 4.9% to 7%. Valid, complete llms.txt files grew from 61 to 82. And the list of AI-Ready domains now includes two names that carry real weight: Cloudflare, which sits at global rank 7, and Adobe at rank 68.
That's the good news, and it's real. Now the honest part. This quarter's crawl reached fewer sites than last time, the average readiness score didn't move, and almost all of the growth is in one file. Two large independent studies published this year argue that hardly anything actually reads llms.txt. We're going to walk through all of it, the growth and the doubts, because a research report that only tells you the flattering half isn't research.
What are AI Discovery Files?
Think of AI Discovery Files as a CV for your website that only machines read.
When ChatGPT, Claude, or Gemini tries to answer a question about your business, it doesn't browse your site the way a person does. It looks for structured, machine-readable signals that state who you are, what you do, what you don't do, and how you'd like to be described. Without those signals, AI systems fall back on inference. Sometimes they infer correctly. Often they don't.
AI Discovery Files close that gap. They're a set of 10 files you publish on your site, each carrying a different part of your machine-readable identity. llms.txt gives AI a structured overview. identity.json provides parseable data about your organisation. brand.txt states what to call you and what not to. ai.txt sets your permissions for how AI can use your content. You don't need all 10 to start, and as the data shows, almost nobody does.
What we measured
On 1 July 2026, we ran the third crawl in our ADF Adoption Research programme. The crawler checked 1,995 domains from the Tranco List, a research-grade domain ranking, split between the global top 1,000 and the UK top 1,000.
Here's the first caveat, and it matters for reading everything below. 1,744 domains responded successfully this quarter, down from 1,905 in Q2. A larger share timed out or errored (251 versus 90), so the sample is smaller and its makeup shifted slightly. Every percentage on this page is calculated against that 1,744, so a few of the softer numbers are partly a function of who answered the door, not a change in behaviour we can prove. We'll flag those as we go rather than dress them up.

For each domain, we checked all 10 AI Discovery File types, validated every file against the published specification, tested robots.txt for AI crawler rules across 15 known AI user agents, and scored each domain on a 0-to-5 readiness tier. Every check is deterministic. The full methodology is published, and the complete Q3 dataset is available with interactive charts and downloadable CSVs.
The growth story: Q2 vs Q3
Here are the numbers side by side.
| Metric | Q2 2026 | Q3 2026 | Change |
|---|---|---|---|
| Sites with any ADF | 7.2% | 9.4% | +2.2pp |
| llms.txt found | 4.9% | 7.0% | +2.1pp |
| llms.txt valid | 3.2% | 4.7% | +1.5pp |
| AI-Ready (Tier 4) | 33 sites | 44 sites | +11 |
| Explicitly allow AI | 23 sites | 31 sites | +8 |
| Schema.org present | 29.7% | 26.3% | -3.4pp |
| Average readiness score | 2.2 | 2.2 | flat |

The top three rows are the real story. llms.txt found rose 2.1 points to 7%, and valid llms.txt rose 1.5 points to 4.7%. Quality kept pace with quantity, which is the part that was missing in our first crawl back in Q1, when most files were broken.
Now the two rows that look like bad news. Schema.org fell from 29.7% to 26.3%, and the average readiness score stayed flat at 2.2. Before anyone reads a decline into that, remember the smaller sample. With 161 fewer sites answering, and a different mix of them, a metric like Schema.org presence can slide without a single site removing its markup. We're not going to claim the web got less structured in three months, because our data can't support that claim. What we can say plainly: the top of the market grew, and the broad middle held steady.
Cloudflare and Adobe join the list
Q2's headline was NVIDIA, Dell, and ASUS entering the AI-Ready list. Q3 goes further up the rankings.
New entrants in the top adopters this quarter include:
- Cloudflare (global rank 7): one of the busiest infrastructure companies on the web, now serving a valid, complete llms.txt
- Adobe (rank 68): a software company whose products sit in front of millions of creative and marketing workflows
- Fox News (rank 450) and Frontiers (rank 917): a major news publisher and an academic publisher
- Dyson (rank 462) and Groupon UK (rank 553): a hardware brand and a marketplace
- Klaviyo (rank 675), Bluehost (rank 666), and Life360 (rank 753): martech, hosting, and consumer apps

Cloudflare matters here beyond its own file. It sits in the request path for a large slice of the web, and when a company at that layer treats an llms.txt as worth publishing, it's a signal to everyone downstream. Adobe matters for a different reason: its tools shape how a lot of other organisations build and describe themselves online. When the AI-Ready list stops being hosting panels and developer tools and starts including news publishers and consumer hardware, the standard has left its original niche.
"Language models can ingest a lot of information quickly, so it can be helpful to have a single place where all of the key information can be collated."
Howard wrote that when he proposed llms.txt in 2024. What strikes me, reading it again with three quarters of crawl data behind us, is how modest the claim actually is. He didn't say the file would boost your rankings or get you cited more. He said it would put your key information in one place a model can read. That's it. A lot of the argument about whether llms.txt "works" is really an argument with a promise nobody serious ever made. Cloudflare and Adobe didn't publish a file to win a ranking. They published one so that when a machine wants the canonical version of who they are, there's a clean answer waiting.
Adoption is still one file deep
Here's the finding that hasn't changed in three quarters, and probably won't for a while. Of the 10 AI Discovery File types we track, only one has meaningful adoption.
- llms.txt: 122 found, 82 valid and complete. This is the whole category.
- llms.html: 46 found, but only 9 valid. Mostly generic HTML pages sitting at the
/llms.htmlpath. - ai.txt and ai.json: 1 to 2 found, none valid
- brand.txt, faq-ai.txt, developer-ai.txt, identity.json: zero to one each
- robots-ai.txt: 1 found, 1 valid

An llms.txt on its own tells AI systems who you are in broad strokes. It can't state what to call you, draw your service boundaries, or set terms for how your content gets used. That's what the supporting files do, and almost nobody has them. It's why zero domains in our sample have reached Tier 5, which needs three or more valid files. The ceiling for a single file is Tier 4, and 44 sites are sitting at it. The next step up is wide open, because so few publishers have gone beyond the one file everyone's heard of. If you want the recommended order, the quick start guide maps it out.
But does anything read these files?
Now the part most quarterly reports would skip. If you've followed the SEO conversation this year, you'll have seen two studies that land hard against llms.txt, and they deserve a straight answer rather than a defensive one.
Ahrefs analysed 137,000 sites and found that of the roughly 38,000 with a valid llms.txt, 97% received no requests for it at all in a single month. Their summary was blunt: "If you publish an llms.txt file today, the most likely outcome by far is that nothing ever fetches it." SE Ranking studied nearly 300,000 domains, put adoption at 10.13% (close to our own figure), and concluded that "llms.txt doesn't impact how AI systems see or cite your content today."
"At Seer, llms.txt files aren't a priority recommendation for most clients. Google has explicitly stated they don't use the file for their AI experiences, and server log audits back that up."
I don't think Pastis is wrong, and that's an uncomfortable thing to write on a site that documents this standard. If your only goal is Google rankings or a bump in AI citations, the evidence says llms.txt won't get you there, and pretending otherwise would be dishonest. When I first read the Ahrefs number, it stung. We've spent a year documenting these files, and here was a careful study saying almost nobody fetches them.
But there are two things the skeptics' framing leaves out. The first is that "nothing fetches it" isn't universal. We run our own AI Discovery Files plugin on mcneece.com, and it logs every AI crawler that touches those files. Here's the last 30 days.

Eleven distinct AI crawlers made 73 requests to those files in a single month, and not one was blocked. Meta's meta-externalagent led with 16, but the crawlers the skeptics say stay away were all present and active during the window.
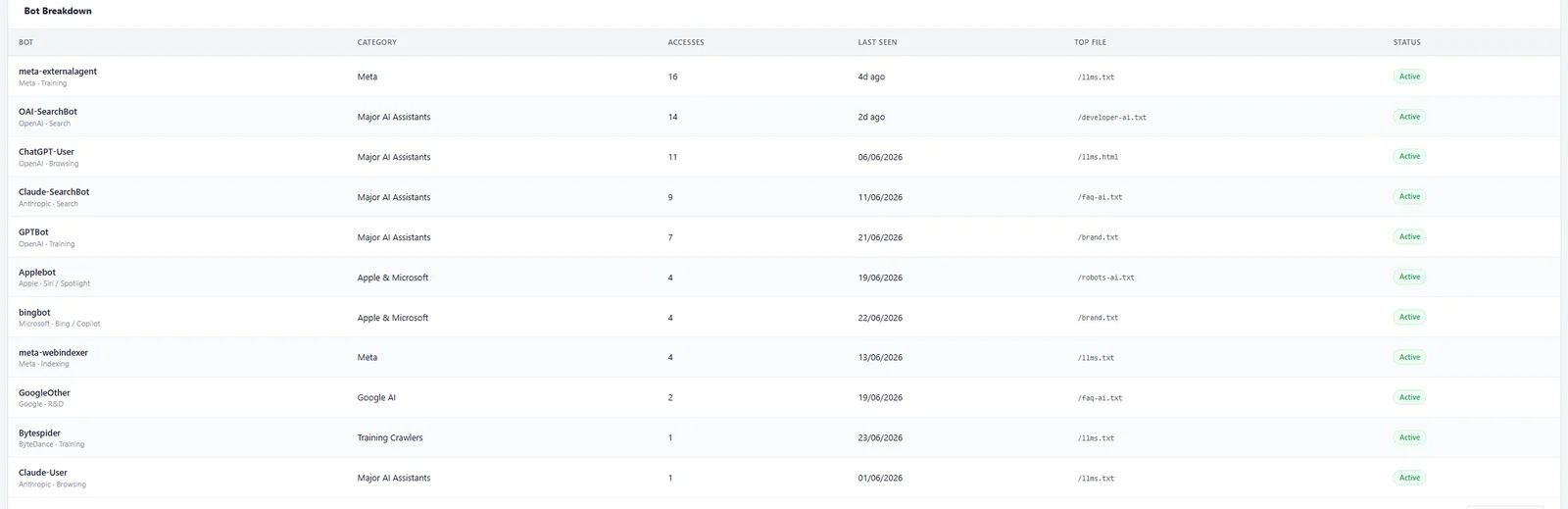
The file-by-file view is the part that matters most. Nine of our ten AI Discovery Files were read, not just llms.txt. brand.txt was fetched 13 times, ai.json and identity.json nine times each, and even the niche developer-ai.txt and robots-ai.txt were pulled. The only file nobody touched was llm.txt, the deprecated singular variant we keep for backwards compatibility.
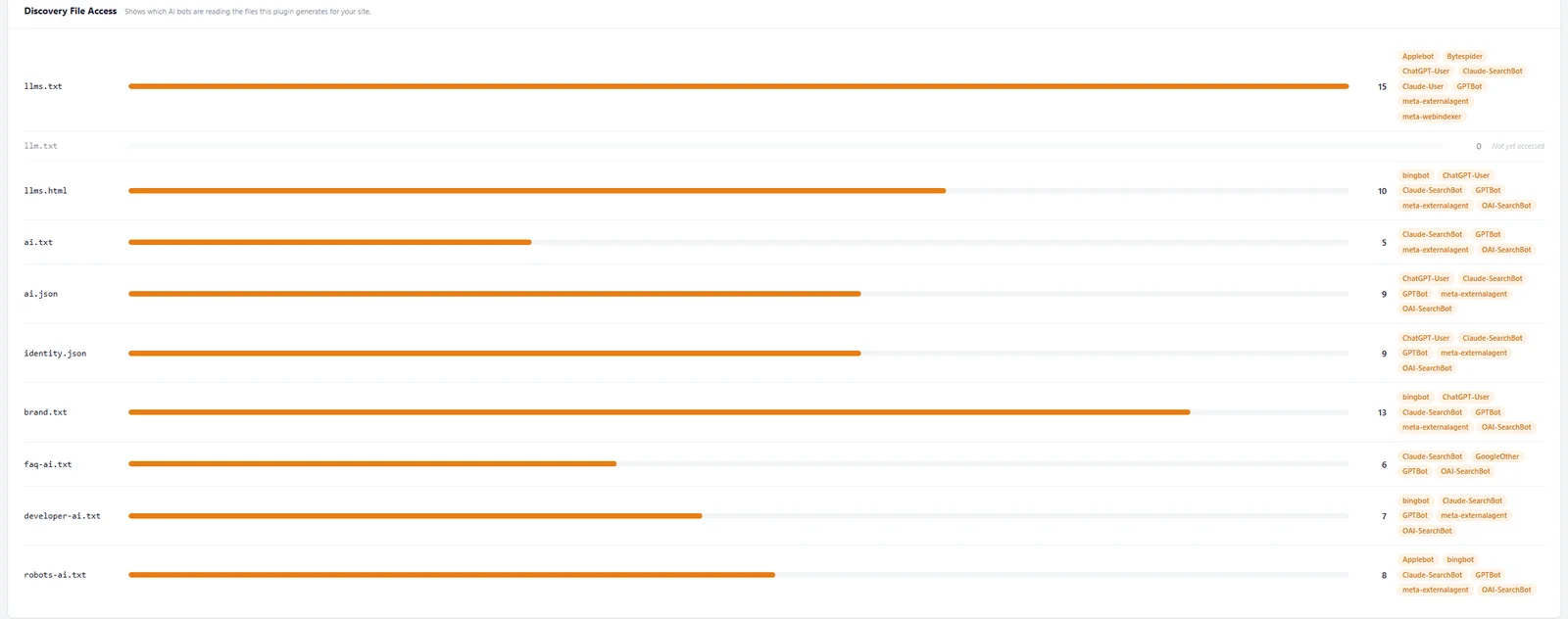
One site isn't 137,000, so this doesn't overturn the Ahrefs finding, and I won't pretend it does. The two results fit together once you separate breadth from depth. Across the whole web, most llms.txt files sit on abandoned or invalid pages that nothing links to, so of course they go unfetched. On a site that's active, valid, and complete, real AI crawlers do come, and they read the whole set. Our earlier 11-day log on a brand-new site showed only Meta and Bing; a month of data on an established site shows the major LLM crawlers arriving too.
The second thing the skeptics leave out matters more, and it's the whole reason this site exists. Those studies measure outputs, rankings and citations. AI Discovery Files are about inputs: whether a machine that does reach your site can identify you correctly. We made that argument in full in what Google actually said about llms.txt and in what AI visibility actually is. A file that isn't fetched today but is correct when it finally is beats a ranking metric that swings every time you refresh the page.
So the balanced read on Q3: adoption is growing, the skeptics are right that citation lift isn't the reason to do it, and the case for these files rests on identity accuracy, not traffic. If someone sells you llms.txt as an SEO tactic, they're measuring the wrong thing.
More of the web is opting in
One quieter number moved in a direction worth watching. Sites that explicitly allow AI crawlers in their robots.txt rose from 23 to 31, lifting the explicit-allow share from 1.2% to 1.8%. Sites with no AI policy at all eased from 85% to 84.2%. Outright blocking barely moved, from 22 sites to 23.

The absolute numbers are small, but the direction is consistent. Where organisations are making a deliberate choice about AI access, more of them are choosing to permit it than to block it. That fits the adoption story: a business that publishes an llms.txt usually wants AI systems to read it, so it makes sense to open the door in robots.txt at the same time. Our robots-ai.txt specification covers how to set granular AI permissions beyond what plain robots.txt allows, and our checklist on whether your site is accidentally blocking AI covers the common mistakes.
Where ADF sits among web standards
Putting the numbers next to established web standards keeps the growth in proportion:
- robots.txt: 50.2% found, 48% valid. The thirty-year-old foundation.
- ads.txt: 16.1% found. Introduced in 2017, pushed by the advertising industry.
- security.txt: 14.6% found. RFC published in 2022.
- AI Discovery Files: 9.4% with any file. llms.txt specifically at 7%.
- humans.txt: 2.3% found. Proposed in 2011, never reached critical mass.
AI Discovery Files have passed humans.txt comfortably and are closing on security.txt. For a standard that only appeared in late 2024, reaching 9.4% is quick. The full comparison with traditional web standards puts this trajectory in historical context. What's different is the driver. robots.txt grew because search engines needed it, and ads.txt grew because the ad industry mandated it. AI Discovery Files are growing because businesses want a say in how AI describes them, which is a slower, more voluntary force, but a durable one. Our expert Q&A on AI Visibility digs into why that matters.
What this means for your website
The competitive bar is still absurdly low. 9.4% of top websites have any AI Discovery File, and 44 sites in our whole sample are AI-Ready. Reaching Tier 4 still puts you ahead of more than 97% of the web's most prominent domains, for something that takes an afternoon. That won't last forever, but it's true today.
Do it for identity, not rankings. The skeptical studies are correct that llms.txt won't lift your citations, so don't buy it as an SEO trick. Buy it as machine-readable identity: the canonical statement of who you are, ready for whichever AI system reads it and whenever that happens. That's a control decision, not a traffic play.
One file is the start, not the finish. Every adopter has an llms.txt and almost none have the supporting files. identity.json, brand.txt, and ai.txt each handle a part of your identity that a single summary can't carry. WordPress users can install our AI Discovery Files plugin to generate the full set, or you can submit a site to the directory once it's live.
We publish updated crawl data every quarter, and the next one is due in Q4 2026. The full research page has trend charts, quarterly reports, and downloadable datasets. If you want to see where your own site stands right now, the checker runs the same validation we use in the crawl.
See where your website stands
The AI Visibility Checker scans for all 10 AI Discovery Files, checks your AI crawler permissions, and scores your readiness. Same checks we use in this research. Free, instant results.
Check your site nowFrequently asked questions
How many websites have AI Discovery Files in 2026?
In our Q3 2026 crawl, 9.4% of the 1,744 top websites we reached have at least one AI Discovery File, up from 7.2% in Q2. The most common file is llms.txt, now on 7% of sites. A separate SE Ranking study of nearly 300,000 domains found a similar figure: 10.13% llms.txt adoption.
Do AI crawlers actually read llms.txt?
It depends whose data you read, and the honest answer is "it depends on the site." Ahrefs analysed 137,000 sites and found 97% of valid llms.txt files got no requests at all in one month. On our own established site, our plugin logged the opposite over 30 days: 11 different AI crawlers, including OpenAI's, Anthropic's, Google's, Microsoft's, and Apple's, made 73 requests and read 9 of our 10 files, with none blocked. Most files across the web sit on abandoned pages nothing links to; an active, valid, complete set does get crawled. See our server-log case study for the detail.
Does llms.txt improve my Google rankings or AI citations?
No, and it was never meant to. SE Ranking found no measurable effect on AI citations, and Google has said it doesn't use the file. That doesn't make the file pointless. AI Discovery Files control the inputs: who you are, what you do, and how you should be described. Ranking and citation counts are outputs. We explain that split in what Google actually said about llms.txt.
Which AI Discovery File should I create first?
Start with llms.txt. It's the most widely adopted file by a wide margin, and our step-by-step guide walks through it in under 30 minutes. After that, add identity.json and brand.txt so AI systems have structured identity rather than a single summary to work from.
Why is adoption still so low if these files are useful?
Two reasons. First, the payoff is invisible on a dashboard: a correct machine-readable identity doesn't show up as a ranking jump, so many teams don't prioritise it. Second, the big skeptical studies have made owners cautious. Adoption is still growing every quarter, but it's concentrated in one file and it hasn't reached the mainstream yet.
What is an AI-Ready site in your scoring?
AI-Ready is Tier 4 on our 0-to-5 readiness scale. It means a domain combines a valid llms.txt, explicit AI crawler permissions, and Schema.org markup. In Q3, 44 domains reached it, up from 33. Zero domains have reached Tier 5, which needs three or more valid AI Discovery Files working together.
How can I check if my website is AI-ready?
Run your domain through the AI Visibility Checker. It scans for all 10 AI Discovery File types, checks your AI crawler permissions, validates identity consistency, and scores your readiness. It's the same validation we use in this research. Free, instant results.
Sources
- AI Discovery File Adoption Research, Q3 2026 - AI Visibility
- AI Discovery File Adoption Research, Q2 2026 - AI Visibility
- Research Methodology - AI Visibility
- /llms.txt, a proposal to provide information to help LLMs use websites - Answer.AI (September 2024)
- We Analyzed 137K Sites: 97% of llms.txt Files Never Get Read - Ahrefs (2026)
- LLMs.txt: Why Brands Rely On It and Why It Doesn't Work - SE Ranking (2026)
- Do llms.txt files actually improve AI search visibility? - Contentful
- Tranco: A Research-Oriented Top Sites Ranking