Everyone agrees on a definition. It's the wrong one.
Search "AI visibility" and you'll meet a striking level of consensus. Tool after tool, post after post, the industry has settled on one meaning: AI visibility is how often an AI assistant mentions your brand. Share of voice. Citation count. The percentage of ChatGPT answers that say your name. It sounds sensible, and the agreement is almost total, which is exactly why it's worth distrusting.
That definition describes an output. It tells you what an AI said about you on a particular day, in answer to a particular prompt, run through a particular model version. Useful to know, sometimes. But it isn't a measure of whether AI systems can see your website properly. It's a measure of the weather, dressed up as a measure of the building.
This site exists to draw that line clearly. AI Visibility Checking is the technical verification of whether a website can be discovered, interpreted, trusted, and safely used by AI systems at all. It's about infrastructure and machine-readable identity, not popularity. The distinction isn't pedantry. Get it wrong and you spend your budget chasing a number that moves on its own, while the thing you could actually fix sits untouched.

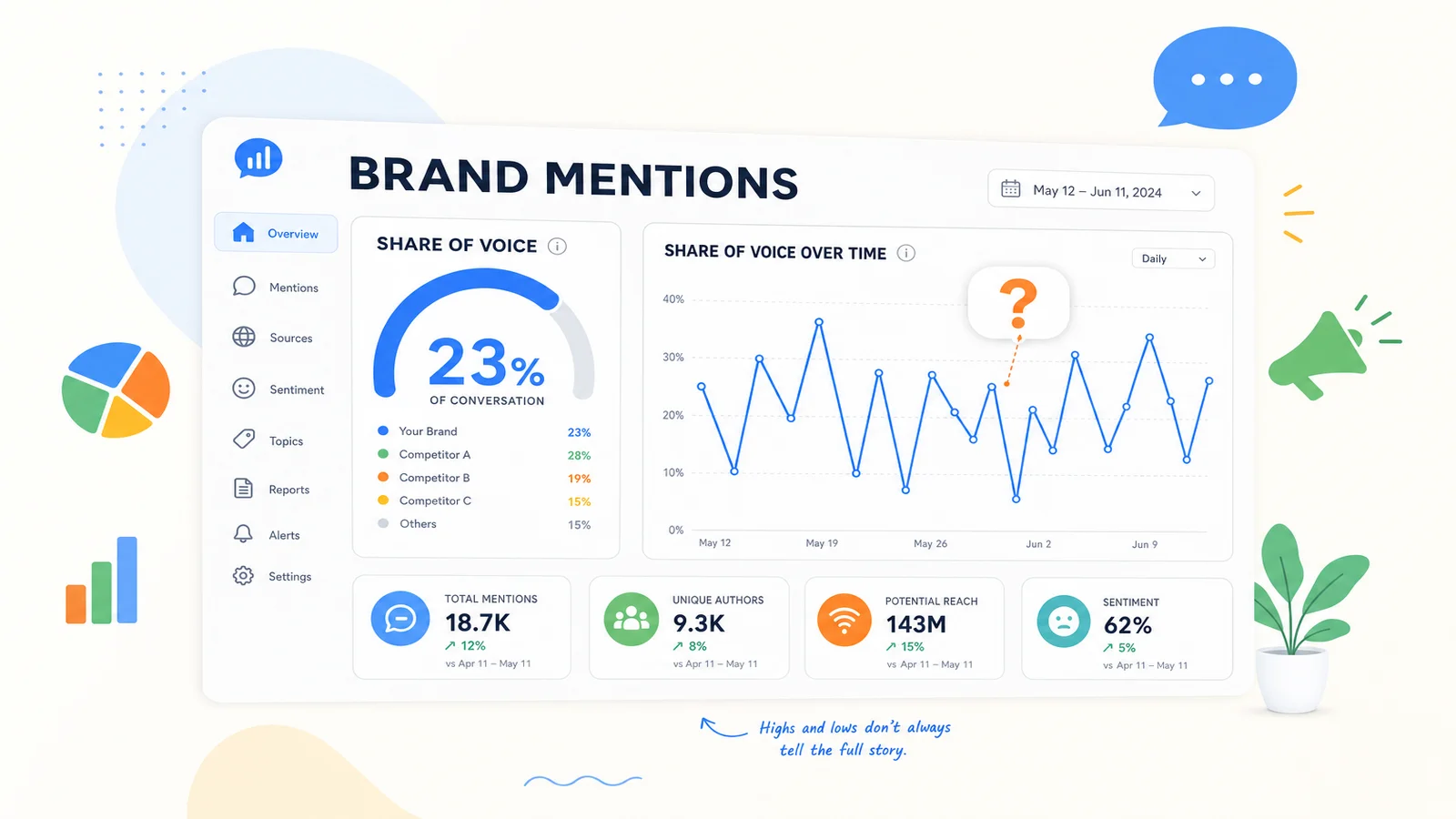
What the tracker tools actually measure
Look at how the popular tools define the term in their own words, and the pattern is consistent. Every one of them is counting mentions.
Profound frames it as tracking "share of visibility, citations, and sentiment" and scores the "percentage of mentions out of the total responses tracked" (tryprofound.com). Peec AI is blunter still: its visibility metric is "the percentage of AI responses that mention your brand" (docs.peec.ai). Semrush defines AI visibility as "how often your brand is mentioned, cited, or recommended in AI-generated responses" (semrush.com). Ahrefs Brand Radar tracks "AI Share of Voice" across AI answers (ahrefs.com). Otterly and AthenaHQ sell the same thing in different packaging: where, and how often, your brand surfaces in AI search (otterly.ai, athenahq.ai).
None of this is dishonest. These are real products measuring a real thing, and brand monitoring has value. The problem is the label. The whole category has taken the phrase "AI visibility" and pinned it to mention-counting, then sold the count as the goal. That leaves the actual question, can an AI read and trust your site, without a name and without a tool. So we gave it one.
Tracking watches outputs. Checking validates inputs.
Here's the split that the whole thing turns on. There are two different jobs hiding under one phrase, and conflating them is how the confusion spreads.
Tracking observes outputs. It watches AI answers over time and reports how often you were named, in what context, with what sentiment. It's a results dashboard. It can't tell you why you were or weren't mentioned, and it can't tell you what to change, because the cause sits upstream of anything it can see.
Checking validates inputs. It inspects the machine-readable signals your site publishes and asks a deterministic question: can an AI system discover this business, interpret it correctly, trust it, and cite it safely? It returns the same answer every time unless the site changes, and every finding maps to something you can fix. That's AI Visibility Checking, and it's what our free AI Visibility Checker does.
One last way to hold the difference in your head. Tracking is the thermometer. Checking is the wiring and the plumbing. A thermometer is worth having, but you don't fix a cold house by staring at it. You fix the house. And the wiring doesn't change every time you walk past, which is more than can be said for the temperature.
The flaw in output metrics: they don't hold still
The deepest problem with defining visibility as mentions isn't philosophical. It's that the measurement is unreliable. Ask the same AI the same question twice and you often get two different shortlists. Build a KPI on that and you've built it on sand.
SparkToro tested this directly across thousands of prompt runs, and Rand Fishkin didn't hedge about what they found.
"AIs do not give consistent lists of brand or product recommendations," and "any tool that gives a 'ranking position in AI' is full of baloney."
Rand Fishkin, Co-founder and CEO of SparkToro, in SparkToro research, January 2026 (verify quote at source)
When I first read that, what struck me wasn't the finding, it was who was saying it. Fishkin built a career on measurement. SEOs trusted his numbers for fifteen years. For him to call an entire metric "baloney" is not a man being contrarian for sport; it's someone who has run the test and seen the noise. We'd already felt the same thing in smaller doses. Re-run a brand prompt across ChatGPT on a Monday and a Thursday and the names reshuffle, drop out, reappear. You can spend a week congratulating yourself on a "share of voice" gain that was a coin landing heads twice. That's when the inputs-versus-outputs argument stopped being a tidy framing for me and started feeling like the only sane place to stand. You cannot manage what you cannot reproduce.

Notice that this cuts in our favour. If outputs fluctuate and inputs are stable, then the responsible thing to measure and manage is the input. You can't promise a client a mention. You can verify, today, that their site is technically legible to the machines that produce mentions. That promise you can keep.
A fair hearing for the other side
It would be cheap to stop there. The inputs-first position has real, intelligent objections, and the post is worth more if it meets the strongest ones rather than the weakest.
Objection one: the files don't get read. The most cited version comes from Google's John Mueller, who poured cold water on llms.txt in 2025.
"AFAIK none of the AI services have said they're using LLMs.TXT (and you can tell when you look at your server logs that they don't even check for it). To me, it's comparable to the keywords meta tag."
John Mueller, Search Advocate at Google, reported in Search Engine Journal, April 2025 (verify quote at source)
Objection two: your own files are a weak signal next to your reputation. Kevin Indig makes this case carefully, arguing that what other people publish about you outweighs what you publish about yourself. "Your owned blog/site is one input; it's a crucial input, but it's likely one of the weakest," he writes, while "the publications, analysts, experts, competitors, and communities that mention you carry significant weight" (Growth Memo, June 2026). Aleyda Solis lands in a similar, balanced place: "structured data helps AI systems understand your entity, but without independent third-party validation from high-authority sources, it's less likely your brand will be surfaced prominently" (aleydasolis.com).
Both objections are partly right, and I'm not going to pretend otherwise. Off-site authority matters. A clean identity.json will not rescue a business nobody trusts. If your only plan is to publish ten files and wait, you'll be disappointed. That isn't the claim.
The rebuttal: Google now scores an AI Discovery File
Take Mueller's point first, because something changed under it. When he made the keywords-meta-tag comparison in early 2025, it was defensible: server logs did show AI services skipping llms.txt. But the ground has moved.
In May 2026 Google added an Agentic Browsing category to Lighthouse and PageSpeed Insights, the tool millions of developers use to grade a site. One of its three checks is the presence of a valid llms.txt. Sit with that for a second. The same company whose advocate called the file pointless is now scoring sites on whether they publish it. You can hold both facts at once, Google doesn't use llms.txt as a ranking factor, and Google now validates llms.txt as an agent-readiness signal, but you can't use the first to claim the file is meaningless while the second is shipping in their own product.
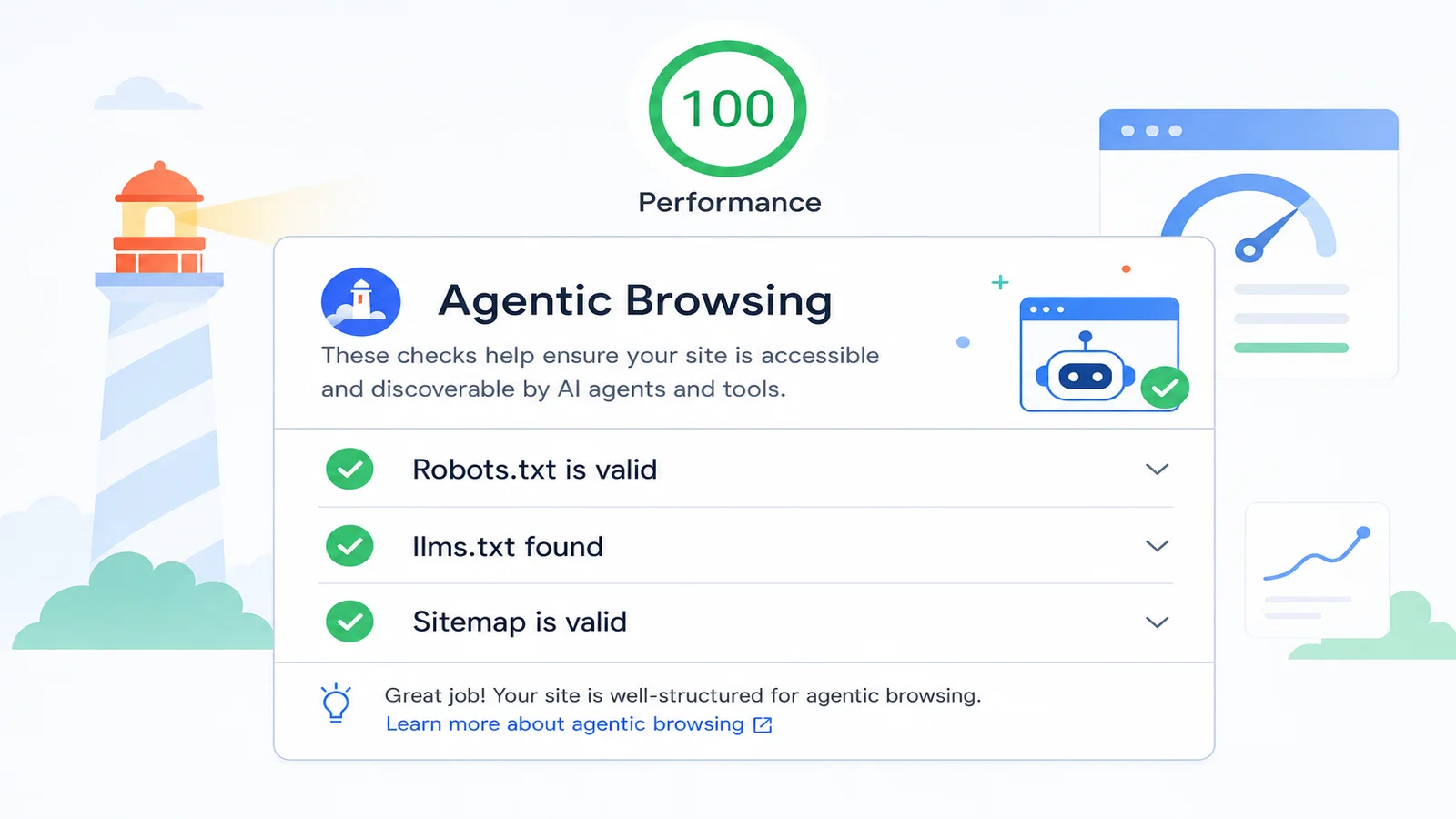
Reading the Agentic Browsing announcement, I'll admit a small, petty satisfaction. We'd spent months being told the files were a vanity project. Then the largest search company on earth quietly added one of them to its scoring rubric. It wasn't vindication exactly, the file was never about pleasing Google, but it was the moment the "nobody reads these" line stopped being safe to repeat. And it lines up with what we'd already seen first-hand: eleven days of server logs showing Meta and Bing crawlers fetching AI Discovery Files day after day.
Now the Indig and Solis objection, which is stronger and deserves a straight answer rather than a dodge. They're right that earned authority drives citations. We've never said files replace reputation. We've said reputation is a different discipline, one that looks like digital PR, and that it sits outside the meaning of the word "checking". Here's the part that matters: of the two, only the inputs can be verified deterministically and fixed this afternoon. You can't make The Guardian cite you by Friday. You can make sure that when any AI does reach your site, it finds one unambiguous identity, valid files, and an open door instead of a blocked crawler. Authority gets you considered. Legible inputs make sure you're not thrown out on a technicality once you are.
Proof: a new site reached the top of AI search with zero backlinks
This isn't theory for us. A locksmith we work with, Lockerfella in Brewood, launched on a brand-new domain in April 2026 with no backlinks, no reviews, and no off-site authority of any kind, into a crowded local trade. Inside ten to twelve days it ranked first in Google, ChatGPT and Gemini for its main local term.
The ranking wasn't even the striking part. The two assistants read the site's real prices and named jobs back almost word for word, which is what happens when a machine can find, parse, and trust what it's looking at. The area pages are the clearest example of why. Each one is written from real call-outs in that town, not a template with the place name swapped in. Look at the pages for Birmingham, Wolverhampton, Cannock and Stafford: named jobs, real streets, the actual price quoted. That is what non-commodity content and visible first-hand experience look like in practice, and it is exactly the kind of specific, well-structured detail an AI will quote with confidence.

By the strict reading of the off-site-authority argument, that site should have stayed invisible to AI for months. It didn't, because the half of the problem you can control had already been closed: valid files, one clear identity, crawlers let in, and pages built from real work rather than templates. I want to be fair about what carried it, because it wasn't the files alone; the bespoke build, the schema, and the genuinely non-commodity area pages all pulled together. But not one of those is off-site authority, and there was none to speak of. The engines cited the site before any reputation existed to lean on. Authority will come, and it'll help when it does. It simply wasn't what got the site read.
What AI Visibility Checking actually validates
So if it isn't mention-counting, what does a real check look at? Four things, all of them inputs, all of them reproducible.
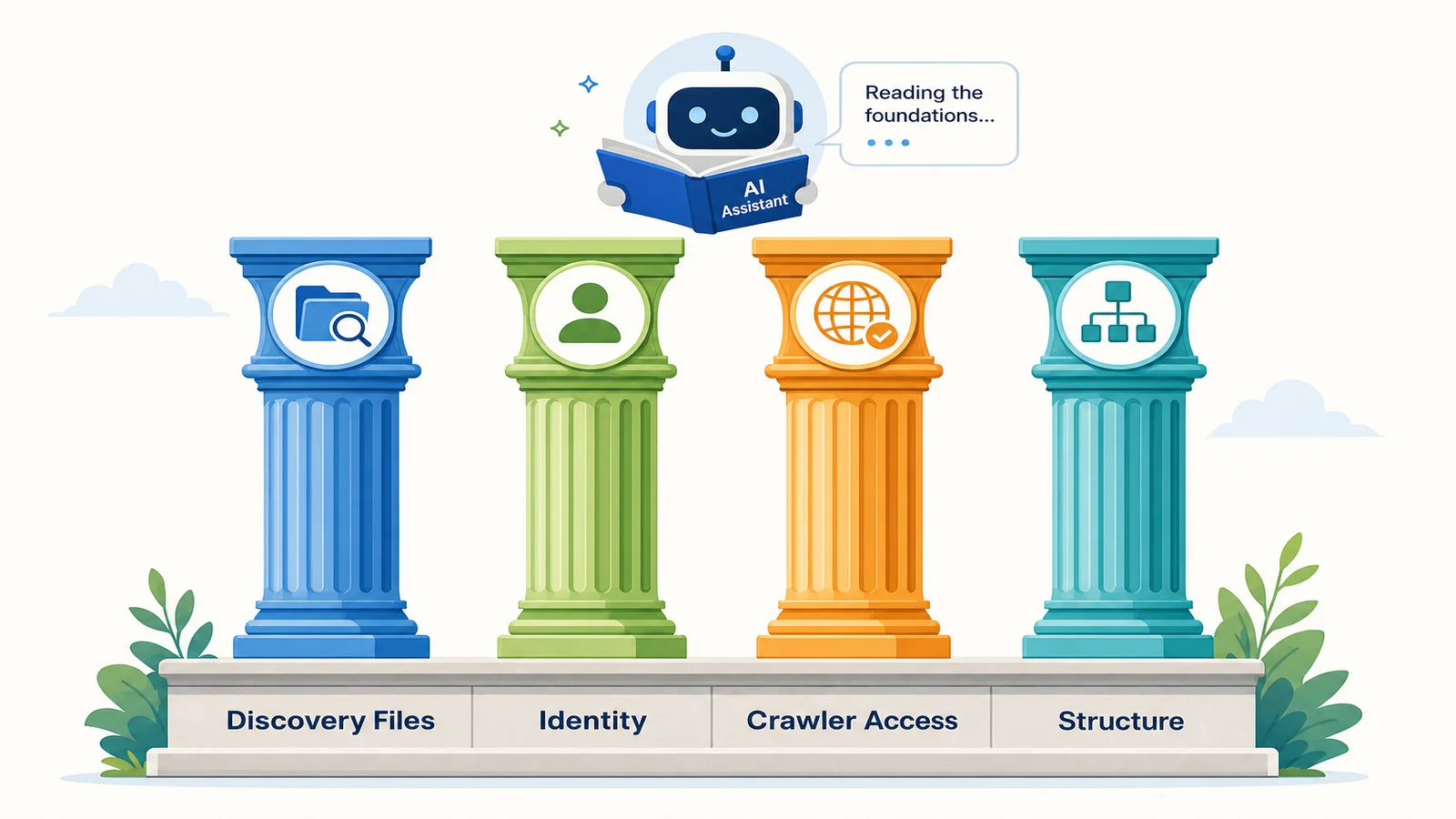
- AI Discovery Files. Are the machine-readable files present and valid? The specification defines ten, from llms.txt to identity.json, each declaring something specific about who you are and how AI may use your content.
- Identity consistency. Does the site state one unambiguous identity, one service area, one set of facts, across every file and page? Contradictions are how an AI ends up guessing, and a guessing model is one that gets you wrong or leaves you out.
- Crawler and access validation. Are AI crawlers allowed in, or quietly blocked by a stray
robots.txtrule? Plenty of sites block the very systems they want to be seen by without realising it. - Structural readiness. Does the page structure support clean, deterministic interpretation, so a machine extracts the same meaning a human reads?
None of those four require you to guess what ChatGPT thinks of you this week. Each is a fact about your site that's true right now and stays true until you change it. That's the whole appeal. It's the half of the problem you can actually close.
The honest version: check the inputs, earn the outputs
Put the two sides together and you get something more useful than either tribe sells on its own. Inputs are necessary but not sufficient. Outputs are the goal but not directly controllable. The mistake the tracker tools make is collapsing the second into the definition and ignoring the first.
Google's own documentation, when you read it plainly, sits on the inputs side of this. To appear in AI Overviews, a page "must be indexed and eligible to be shown in Google Search with a snippet, fulfilling the Search technical requirements" (Google Search Central). That's a technical input gate, not a popularity contest. And structured data, Google says, is how it "understands the content of the page" (Google Search Central). Machine-readability is the price of admission. Authority decides the seating.
So here's the working order we'd actually defend. Check the inputs first, because they're verifiable, fixable, and stable, and because there's no point earning a mention that points an AI at a site it can't read. Then earn the outputs through the slow, real work of reputation. Track the outputs if you like, with clear eyes about the noise, treating them as a lagging signal rather than a steering wheel. The team that does the first part is rare. The businesses that get it right tend to be small and deliberate, not large and famous, which tells you the inputs are a real lever and not a proxy for budget.
AI visibility, the real thing, is whether the machines can see you clearly. Not whether they happened to applaud. If you only do one thing, check the inputs. It's the half you can actually act on, and it's free to find out where you stand. You can also add your site to the AI Visibility Directory once it passes, and read the broader picture from 365i, the team that wrote the specification.
Frequently asked questions
What is AI visibility?
AI visibility is whether a website can be discovered, interpreted, trusted, and safely used by AI systems such as ChatGPT, Claude, Gemini, and Perplexity. It is a property of your site's machine-readable inputs, not a count of how often an assistant happens to mention your brand. The full definition of AI Visibility Checking sets out the four things it covers.
Is AI visibility the same as brand mentions in AI answers?
No. Brand mentions, share of voice, and citation counts are outputs: they describe what an AI happened to say on the day you asked, and they change from run to run. That activity is AI visibility tracking. AI Visibility Checking validates the inputs that make a site legible to AI in the first place. One observes results; the other verifies capability.
Do AI systems actually read llms.txt and other AI Discovery Files?
Some do and some do not, and it is changing quickly. We logged Meta and Bing crawlers fetching AI Discovery Files daily over 11 days of real server logs. More tellingly, Google's own PageSpeed Insights now scores llms.txt as one of three checks in its Agentic Browsing category. Even sceptics agree the files are read by some agents; the trend is toward more, not fewer.
Did Google say llms.txt is useless?
John Mueller compared llms.txt to the keywords meta tag in 2025, and Gary Illyes said normal SEO is what ranks in AI Overviews. That is a fair note about ranking inside Google's own systems. It is not the whole question. In May 2026 Google added an Agentic Browsing score to PageSpeed Insights that checks for llms.txt, so Google is now validating the file even while telling people it is not a ranking factor. What Google actually said about llms.txt separates the two.
Why do inputs matter more than outputs for AI visibility?
Because outputs are not reproducible and inputs are. Research from SparkToro found AI tools rarely return the same brand list twice for the same prompt. A metric built on that moves under your feet. Inputs, the files and signals your site publishes, stay put and are the part you actually control. Fix the inputs and you have done the work that lasts.
Do brand mentions and authority still matter?
Yes. Off-site reputation, citations from trusted publications, and consistent brand language all help an AI decide to recommend you. We do not dispute that. The point is that earned authority is a separate discipline, closer to digital PR, and it is not what the word "checking" describes. You need both: verifiable inputs and earned authority. Only one of them can be checked deterministically today.
How do I check my own site's AI visibility?
Run the free AI Visibility Checker. It fetches your AI Discovery Files, validates each one, confirms your business identity is consistent, and checks that AI crawlers are allowed in. It finishes in under a minute, needs no account, and returns the same result every time unless your site changes.
What is the difference between AI Visibility Checking, GEO, and AEO?
GEO (generative engine optimisation) and AEO (answer engine optimisation) are mostly output-focused: they aim to increase mentions and citations in AI answers. AI Visibility Checking is input-focused: it verifies the technical groundwork that lets AI read you correctly at all. They are complementary. AI Visibility vs SEO covers where these disciplines meet and where they part.
Sources
- New Research: AIs Are Highly Inconsistent When Recommending Brands or Products - SparkToro (Rand Fishkin)
- Google Says LLMs.txt Comparable To Keywords Meta Tag - Search Engine Journal
- Topics Matter For Third-Party Authority - Growth Memo (Kevin Indig)
- Characteristics of AI Search Winning Brands - Aleyda Solis
- How to Track Your Visibility in AI Search - Profound
- Visibility metric - Peec AI documentation
- What is AI Visibility - Semrush
- Brand Radar - Ahrefs
- AI features and your website - Google Search Central
- Intro to structured data - Google Search Central