
The problem AI Discovery Files solve
When someone asks ChatGPT, Claude, or Gemini about your business, the AI has to answer with whatever information it can find. If your website doesn't provide explicit, machine-readable signals about who you are and what you do, the AI is left to guess.
The results are predictable. Services get conflated. Brand names get misspelled. Locations are wrong. Entire product lines are fabricated. A plumber in Bristol gets described as offering gas boiler installation when they only handle drainage. A solicitor's firm gets credited with practice areas they abandoned years ago.
This isn't a failure of the AI. It's a failure of the information environment. AI systems are remarkably good at extracting meaning from text, but they can't reliably infer the difference between what a business does and what it merely mentions on its website. When a page discusses competitors, industry trends, or services the business explicitly doesn't offer, the AI has no way to distinguish those references from the business's own identity unless the business makes that distinction explicit.
The problem grows worse as AI adoption accelerates. More people rely on AI-generated answers for purchasing decisions, referrals, and research. If your business is being described inaccurately in those answers, you're losing trust and revenue to a problem that's entirely preventable.
What are AI Discovery Files?
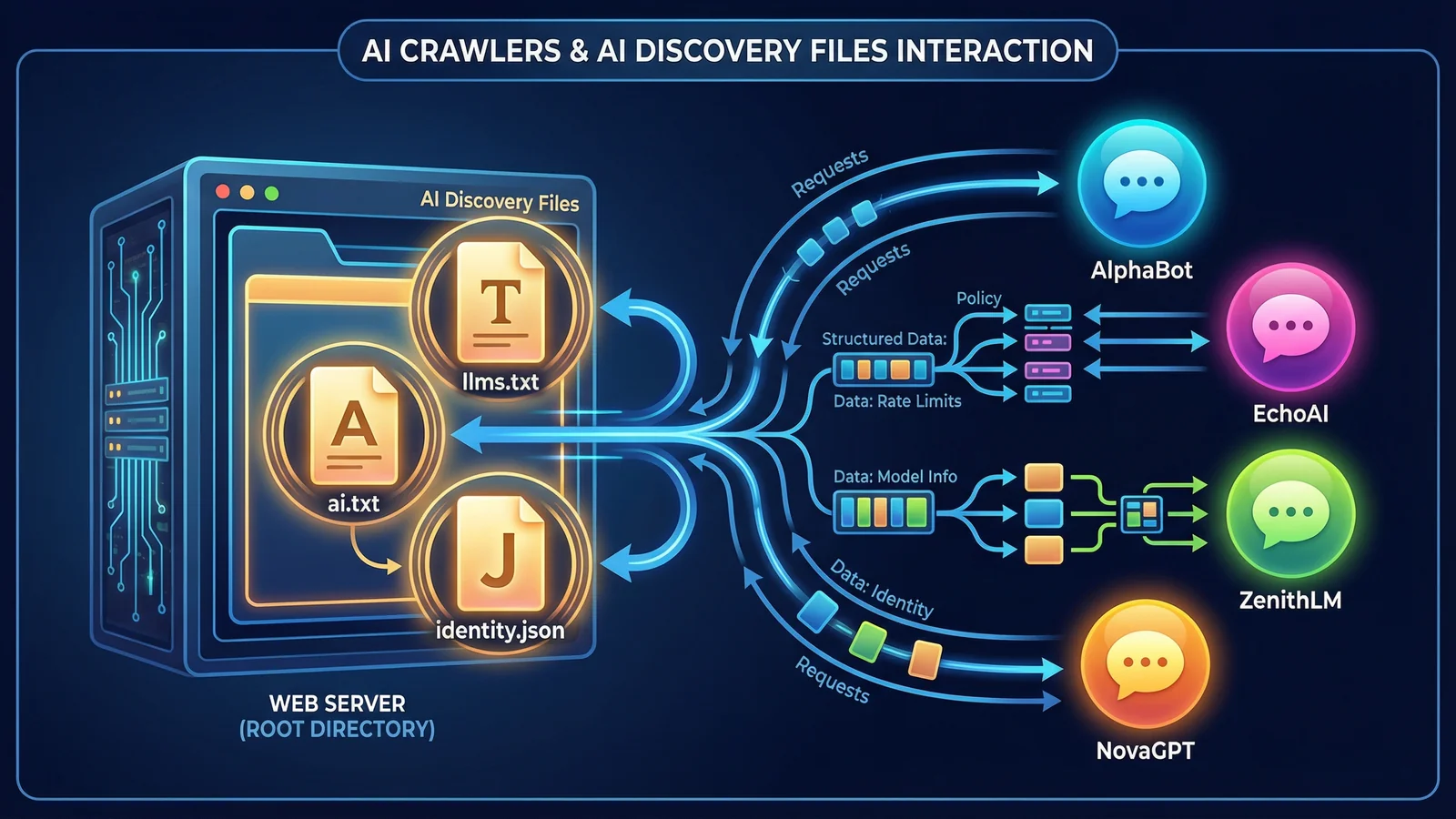
AI Discovery Files are a set of machine-readable files placed in your website's root directory that tell AI systems who you are, what you do, and how to represent you accurately. They provide structured, unambiguous signals that AI crawlers can parse without interpretation or guesswork.
The concept was developed and coined by 365i as part of the broader AI Visibility framework. Where traditional web standards like robots.txt and sitemap.xml help search engine crawlers navigate your site, AI Discovery Files serve a different purpose: they help AI systems understand your site.
Each file addresses a specific dimension of your online identity. Some declare your business name, services, and location. Others specify how AI systems should cite your brand. Others still define which AI crawlers have permission to access your content and under what conditions. Together, they form a complete, deterministic identity layer that sits alongside your existing website infrastructure. For a broader look at what AI Visibility means and why it matters, see our expert Q&A with Mark McNeece.
The term "discovery" is deliberate. These files aren't about optimisation, ranking, or persuasion. They're about making your business discoverable in a way that's accurate, consistent, and verifiable. You're not trying to influence what an AI says about you. You're giving it the correct information to begin with.
"Your web pages have an underlying meaning that people understand when they read the web pages. But search engines have a limited understanding of what is being discussed on those pages."
Schema.org was built to bridge the gap between what humans understand and what search engines can parse. AI Discovery Files address the same problem for a different audience. Schema.org embeds structured data within your HTML pages. AI Discovery Files sit alongside your pages as standalone documents that AI crawlers can fetch independently. If search engines had "a limited understanding" of your pages in 2011, AI systems face an even bigger version of that problem today. They're not just indexing your content; they're synthesising answers from it, citing it, and recommending your business based on it.
There are 10 AI Discovery Files in total, each identified by a code from ADF-001 to ADF-010. The full technical specifications for each file are published at ai-visibility.org.uk/specifications.
The 10 AI Discovery Files
The table below lists all 10 files, their specification codes, and what each one does.
| Code | File | Purpose |
|---|---|---|
| ADF-001 | llms.txt |
Project description for large language models |
| ADF-002 | llm.txt |
Condensed single-page identity summary |
| ADF-003 | llms.html |
Human-readable AI discovery information |
| ADF-004 | ai.txt |
AI permissions and usage policy |
| ADF-005 | ai.json |
Machine-parseable AI permissions and metadata |
| ADF-006 | identity.json |
Structured business identity data |
| ADF-007 | brand.txt |
Brand naming and terminology rules |
| ADF-008 | faq-ai.txt |
Pre-answered frequently asked questions |
| ADF-009 | developer-ai.txt |
Technical context for developer-facing AI tools |
| ADF-010 | robots-ai.txt |
AI-specific crawler access rules |
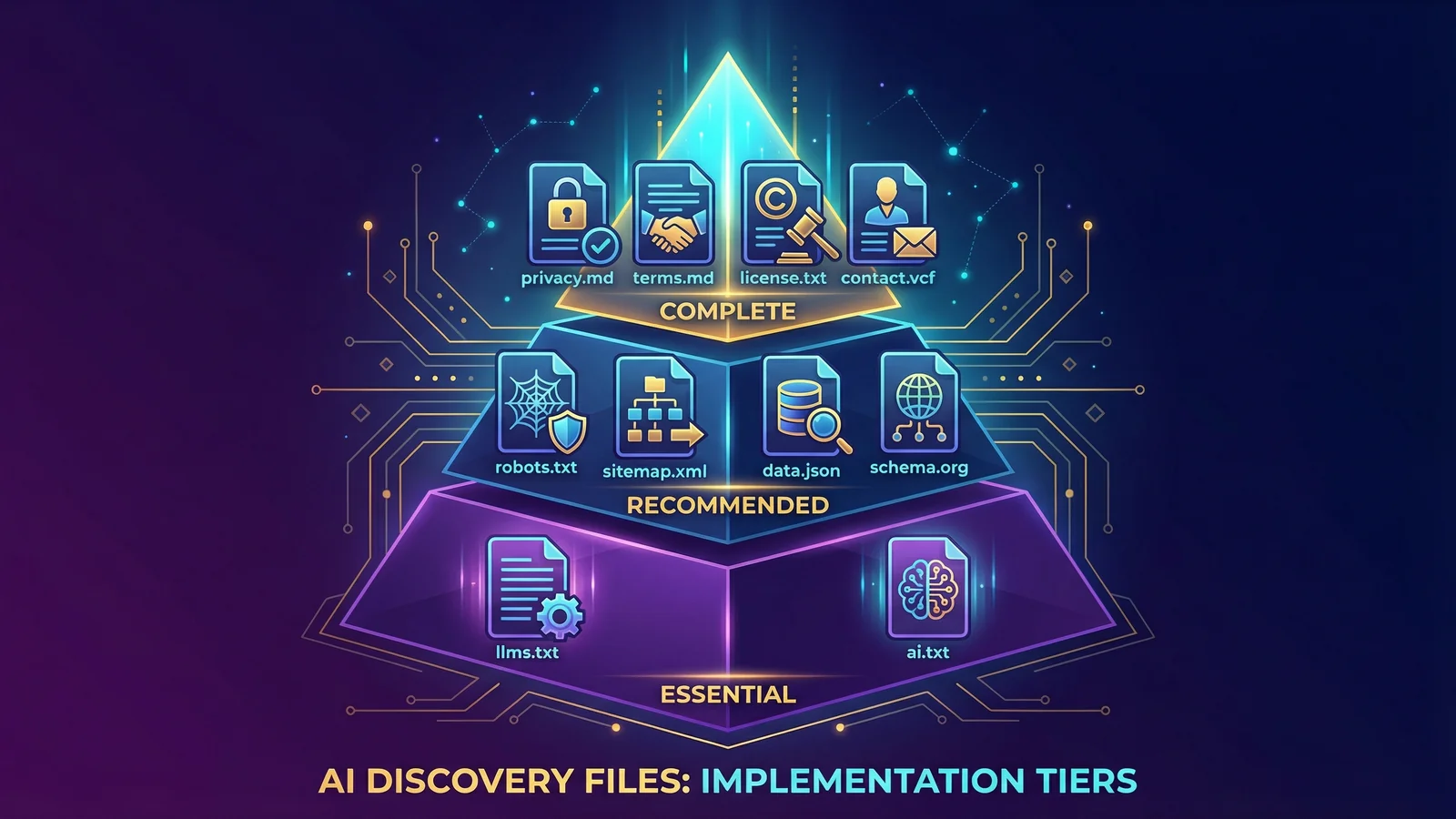
You don't need all 10 files to get started. The files are grouped into three tiers based on priority: essential, recommended, and complete.
Essential files (start here)
If you implement only two AI Discovery Files, these are the two that matter most.
llms.txt (ADF-001) is the foundational file. It provides a structured plain-text description of your business that large language models can read directly. Think of it as the AI equivalent of your homepage, except written specifically for machines rather than humans. It declares your business name, a summary of what you do, your key pages, and any important context an AI system would need to represent you accurately.
The format is simple. Here's a minimal example:
# Example Business Ltd
> A Bristol-based plumbing company specialising in domestic
> drainage repairs and emergency callouts. Established 2004.
## Services
- [Emergency Drainage](https://example.com/emergency-drainage/)
- [Drain Repairs](https://example.com/drain-repairs/)
- [CCTV Drain Surveys](https://example.com/cctv-surveys/)
## Important Context
- We do NOT install or service gas boilers
- We operate in Bristol, Bath, and North Somerset only
- 24/7 emergency callout availableThe "Important Context" section is particularly valuable. It gives you a place to state explicitly what your business does not do, preventing the kind of hallucinated services that occur when AI systems over-generalise. See the full llms.txt specification for the complete format reference.
ai.txt (ADF-004) declares your permissions and policies for AI systems. It tells AI crawlers whether they may use your content for training, retrieval, or citation, and under what conditions. It also specifies your preferred attribution format.
# ai.txt - Example Business Ltd
# https://example.com/ai.txt
User-Agent: *
Allow-Training: no
Allow-Retrieval: yes
Allow-Citation: yes
Attribution: Example Business Ltd (https://example.com)
Contact: hello@example.comWithout ai.txt, AI systems have no way to know your preferences about how your content is used. Some may train on it without permission. Others may cite it without proper attribution. This file makes your position explicit. See the full ai.txt specification for all supported directives.
Recommended files
Once the essential files are in place, these four files considerably strengthen your AI identity.
identity.json (ADF-006) provides your business identity as structured JSON data. It includes your legal name, trading name, business type, registration numbers, address, contact details, and services in a format that is unambiguous and machine-parseable. Where llms.txt is a narrative description, identity.json is a data record. AI systems can cross-reference the two for consistency. See the identity.json specification.
brand.txt (ADF-007) specifies exactly how your brand name should be written, what abbreviations are acceptable, and what alternative names should never be used. If your company is "365i" and AI systems keep writing "365I", "365-i", or "Three-Six-Five-Eye", this file prevents that. See the brand.txt specification.
robots-ai.txt (ADF-010) provides granular, AI-specific crawler access rules that go beyond what robots.txt can express. You can allow one AI crawler while blocking another, permit retrieval but deny training, or restrict access to specific sections of your site. See the robots-ai.txt specification.
llms.html (ADF-003) is the human-readable counterpart to llms.txt. It presents the same AI discovery information in HTML format, making it accessible to both people and AI systems that prefer structured markup. It serves as a transparency page: visitors can see exactly what you're telling AI systems about your business. See the llms.html specification.
Complete implementation
The remaining four files round out a complete AI identity.
ai.json (ADF-005) is the machine-parseable equivalent of ai.txt. It expresses the same permissions and policies in JSON format, making it easier for automated systems to consume. Use both ai.txt and ai.json for maximum compatibility. See the ai.json specification.
faq-ai.txt (ADF-008) provides pre-answered questions about your business in a structured format. Rather than letting AI systems guess the answers to common questions, you supply the correct responses directly. This is especially valuable for businesses that are frequently asked about pricing, availability, service areas, or qualifications. See the faq-ai.txt specification.
developer-ai.txt (ADF-009) provides technical context for AI-powered development tools like GitHub Copilot, Cursor, and similar code assistants. If your business provides APIs, SDKs, or developer-facing services, this file helps AI coding tools understand your technical documentation accurately. See the developer-ai.txt specification.
llm.txt (ADF-002) is a condensed, single-page version of llms.txt. It provides a brief identity summary suitable for AI systems that process individual pages or have limited context windows. Think of it as the elevator pitch version of your AI identity. See the llm.txt specification.
How AI Discovery Files work
The mechanism behind AI Discovery Files is simple. AI systems operate crawlers that fetch and index web content, much as search engine crawlers do. When an AI crawler visits your website, it checks well-known file paths in the root directory, just as Googlebot checks /robots.txt and /sitemap.xml.
If an AI crawler finds your llms.txt file at https://example.com/llms.txt, it parses the contents and stores the structured information alongside whatever else it has learned from crawling your pages. The same applies to ai.txt, identity.json, and the other files. Each one provides a different facet of your identity in a format optimised for machine consumption.
The next time someone asks the AI a question that involves your business, the system can reference these structured signals rather than relying solely on inferences drawn from unstructured page content. Your business name comes from identity.json, not from a best guess at your page title. Your services come from llms.txt, not from keyword extraction. Your brand spelling comes from brand.txt, not from whatever variation appeared most frequently in training data.
Key distinction
AI Discovery Files don't influence rankings, prompt outcomes, or how often your business appears in AI responses. They influence accuracy. The goal isn't to be mentioned more frequently but to be described correctly when you are mentioned. This is the distinction between AI Visibility Checking (validating capability) and AI Visibility Tracking (measuring outcomes).
Because these files use standardised formats and well-known paths, they are deterministic and verifiable. You can check whether your files exist, whether they parse correctly, and whether their content is consistent across formats. There's no black box. The AI Visibility Checker performs exactly this kind of validation. For a worked example of all 10 files used together on a real production site, see our case study of a three-week-old locksmith site that topped AI search.
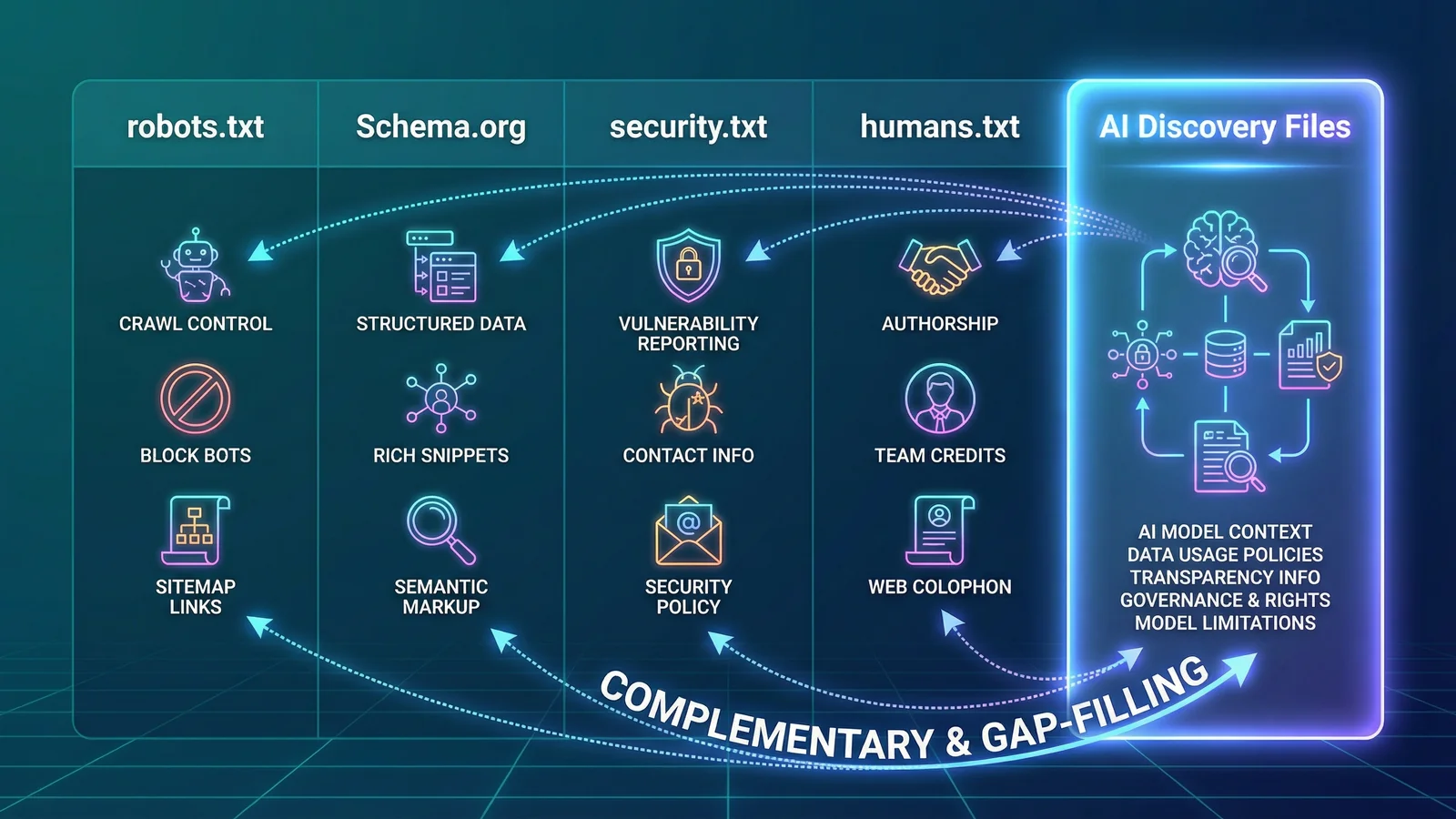
AI Discovery Files vs existing web standards
A common question is whether AI Discovery Files replace existing standards like robots.txt, Schema.org markup, or security.txt. They don't. AI Discovery Files are designed to complement your existing web infrastructure, not replace it.
| Standard | Purpose | AI Discovery File equivalent |
|---|---|---|
robots.txt |
Crawler access control | robots-ai.txt adds AI-specific granularity |
| Schema.org | Structured data in HTML pages | identity.json provides standalone structured identity |
security.txt |
Security contact disclosure | ai.txt provides AI usage policy disclosure |
humans.txt |
Human-readable team credits | llms.txt provides machine-readable business description |
sitemap.xml |
Page discovery for crawlers | llms.txt provides curated page list for AI context |
The important principle is that robots.txt tells crawlers where they can go, while robots-ai.txt tells AI crawlers what they can do with what they find. Schema.org describes the content of individual pages, while identity.json describes the business as a whole. These are complementary layers, not competing ones.
For a detailed comparison with worked examples, see AI Discovery Files vs Web Standards.
"Google uses structured data that it finds on the web to understand the content of the page, as well as to gather information about the web and the world in general."
Google doesn't just use structured data for rich results; they use it "to gather information about the web and the world in general." That sentence matters more now than when it was written. AI Overviews, Knowledge Panels, and AI-generated answers all rely on the same kind of structured signals. But Google's structured data lives inside your HTML. AI Discovery Files extend the same principle to a format any AI system can fetch, whether it's Google, ChatGPT, Claude, or Perplexity. If structured data already helped your search presence, standalone identity files are the next logical step.
Which files do you need?
The right set of files depends on your business and how much control you want over your AI representation. Here are three implementation levels to help you decide.
| Level | Files | Best for |
|---|---|---|
| Minimal | llms.txt, ai.txt |
Any business that wants AI systems to get the basics right |
| Recommended | Minimal + identity.json, brand.txt, robots-ai.txt, llms.html |
Businesses where brand accuracy and AI permissions matter |
| Complete | All 10 files | Businesses with developer audiences, complex service offerings, or strict compliance requirements |
A practical way to decide is to ask yourself three questions:
- Do AI systems currently describe your business accurately? If not, start with
llms.txtandidentity.json. - Do you care how AI systems use your content (training vs citation)? If yes, add
ai.txtandrobots-ai.txt. - Is your brand name frequently misspelled or confused? If yes, add
brand.txt.
For most businesses, the recommended set of six files provides strong coverage without unnecessary complexity. You can always add the remaining files later as your needs evolve.
Check your AI Discovery Files
The free AI Visibility Checker scans your website and reports which files are present, which are missing, and whether they contain any errors.
Run a free checkHow to get started
How you implement AI Discovery Files depends on your technical confidence and the platform your website runs on.
Create them manually
If you are comfortable editing text files and uploading them to your web server, you can create each file yourself. The specifications at ai-visibility.org.uk/specifications document the exact format, required fields, and validation rules for every file.
For a practical walkthrough of the most important file, see How to Create Your llms.txt File: A Step-by-Step Guide. That tutorial covers the format, common mistakes, and how to verify your file works correctly.
Use the WordPress plugin
If your website runs on WordPress, the AI Discovery Files plugin generates and manages all 10 files automatically. It pulls your business information from a settings panel and outputs correctly formatted files at the right paths. Updates are handled through the WordPress admin interface, and the plugin validates your content as you go.
Use the professional service
If you want expert implementation without the technical overhead, the AI Discovery Files Service Pack from 365i handles everything. The team creates, validates, and deploys all 10 files based on a detailed intake questionnaire about your business. This is the fastest route to complete coverage and is particularly suited to businesses with complex service offerings or multiple locations.
Not sure where to start?
Run a free check on your website to see which AI Discovery Files you already have, which ones are missing, and what to prioritise first.
Check your website nowFrequently asked questions
Are AI Discovery Files a web standard?
AI Discovery Files are an emerging convention, not a ratified W3C or IETF standard. However, several of the individual files draw on established conventions. llms.txt follows the pattern proposed by Jeremy Howard and adopted by a growing number of websites. ai.txt follows the disclosure model of security.txt (RFC 9116). The formats are designed to be simple, predictable, and easy for any AI system to consume, which is what drives adoption in practice. The full specifications are published openly at ai-visibility.org.uk/specifications.
Do AI systems actually read these files?
Yes. AI crawlers from OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended), and others actively crawl the web and fetch files from well-known paths. llms.txt in particular has seen rapid adoption, with major AI providers acknowledging it as a signal source. The ADF Adoption Research published on this site tracks real-world adoption rates across thousands of websites. As with any web convention, broader support follows adoption. The more websites publish these files, the more AI systems build them into their processing pipelines.
Will AI Discovery Files improve my search rankings?
No. AI Discovery Files have no direct effect on search engine rankings. They aren't an SEO tool. Their purpose is to improve the accuracy of how AI systems represent your business, not to increase your visibility in search results. That said, the discipline of clearly defining your business identity, services, and brand guidelines often surfaces inconsistencies that, once resolved, benefit your broader online presence indirectly.
How often should I update my AI Discovery Files?
Update your files whenever your business information changes: new services, discontinued services, a name change, an address change, updated contact details, or revised AI usage policies. For most businesses, a quarterly review is sufficient. If your files are managed by the WordPress plugin, updates are as simple as editing a settings page. The important thing is that your files remain consistent with your actual business. Stale or contradictory files are worse than no files at all.
Can AI Discovery Files conflict with my robots.txt?
They can, and this is one of the things the AI Visibility Checker specifically tests for. If your robots.txt blocks an AI crawler but your ai.txt grants it permission to use your content, that's a contradiction. AI systems will typically respect robots.txt as the authoritative access control, but the inconsistency sends mixed signals. Best practice is to ensure your robots.txt, robots-ai.txt, and ai.txt all express a consistent policy.
Do I need all 10 files?
No. Most businesses achieve strong AI visibility with just the essential pair (llms.txt and ai.txt) or the recommended set of six files. The remaining files add depth for specific use cases: faq-ai.txt is valuable if your business faces frequent questions; developer-ai.txt matters if you serve a developer audience. Start with the essentials, run the free checker, and expand as needed. See the implementation guide above for a decision framework.
What if my AI Discovery Files contain errors?
Errors in your AI Discovery Files can be worse than having no files at all. If your llms.txt lists incorrect services, AI systems may repeat those inaccuracies with more confidence than they would if they were guessing. If your identity.json has malformed JSON, crawlers will silently ignore it and fall back to inference. Always validate your files after creating or updating them. The AI Visibility Checker tests for format errors, missing required fields, and contradictions between files.