
The headline finding
We crawled nearly 2,000 of the web's most prominent domains to answer a simple question: how prepared is the internet for AI?
The answer is worse than we expected. Not because websites aren't trying, but because most of the ones that are trying are getting it wrong.
6.5% of the top websites we analysed have at least one AI Discovery File. That's 95 domains out of 1,460 successfully crawled. But of the 100 files we found across those domains, 56 are invalid. Broken syntax, URL dumps, placeholder content, missing required fields. More than half the files that exist don't actually work.
Zero domains in our sample reached Tier 5 (AI-Optimised). The highest tier achieved was Tier 4 (AI-Ready), occupied by just 22 sites. That's 1.5% of the sample. The remaining 98.5% either haven't started, have started badly, or simply haven't considered it yet.
The gap isn't awareness. It's quality.
What we measured
In February 2026, we ran the first quarterly crawl of AI Discovery File adoption as part of our ongoing ADF Adoption Research programme. The full dataset, downloadable CSVs, and interactive charts are available on the Q1 2026 research page.
The crawl covered 1,995 unique domains drawn from the Tranco List, a research-grade domain ranking that aggregates multiple popularity lists to resist manipulation. We split the sample evenly: the global top 1,000 and the UK top 1,000, with overlap removed. 1,460 domains responded successfully.
For each domain, we checked all 10 AI Discovery File types, validated each one against the published specification, tested robots.txt for AI crawler policies across 15 known AI user agents, checked for Schema.org markup on the homepage, and computed an AI Readiness Tier from 0 to 5.
Every check is deterministic. No opaque scores, no prompt variance, no black-box weighting. The full methodology is published and reproducible.

Adoption by file type
llms.txt leads by a wide margin. 55 domains serve one (3.8% of those crawled), making it the most adopted AI Discovery File. That tracks with what we'd expect. It's the file AI systems are most likely to request, and it has the most visibility in developer and SEO communities.
llms.html follows at 41 domains found (2.8%), but the quality story here is grim. Only 7 of those 41 are valid. Just 1 is complete. The remaining 34 are invalid, most serving a generic HTML page that happens to live at the /llms.html path rather than an actual structured companion file.
Beyond those two, adoption drops to near zero:
- ai.txt: 1 found, 0 valid
- ai.json: 1 found, 0 valid
- robots-ai.txt: 1 found, 1 valid
- identity.json, brand.txt, faq-ai.txt, developer-ai.txt: 0 found across all 1,460 domains
The concentration is stark. The web has discovered llms.txt but hasn't yet explored the rest of the specification. That matters, because a single file can't carry the full weight of machine-readable identity. An llms.txt tells AI systems who you are in broad strokes. An identity.json gives them structured data. A brand.txt tells them what to call you and what not to call you. Without the supporting files, AI systems are still guessing on the details.
The quality gap
This is the finding that changed how we think about the data.
Across all 1,460 domains, we checked 14,600 file URLs (10 file types per domain). The breakdown:
- 14,500 returned 404 or were not found
- 56 were found but invalid
- 8 met minimum requirements only
- 36 were complete and specification-compliant
That means 56% of the files that exist are broken. Not missing; present and broken. They're serving content at the right URL, with the right filename, returning HTTP 200. But the content inside fails validation.

The llms.txt failure rate tells the story most clearly. Of 55 files found, 20 are invalid. That's a 36% failure rate on the most well-known file in the specification. Common issues we see: raw URL lists with no Markdown structure, copy-pasted sitemaps, files under 50 words with no meaningful content, and placeholder text from tutorials that was never replaced.
"The Semantic Web is not a separate Web but an extension of the current one, in which information is given well-defined meaning, better enabling computers and people to work in cooperation."
Berners-Lee wrote that twenty-five years ago. When we first read it during the early planning for this research, it felt more like a description of what AI Discovery Files are trying to achieve than anything written in this decade. Information with "well-defined meaning" that enables computers and people to cooperate. That's the entire premise of the specification.
And yet, a quarter of a century later, 56% of the files attempting to give information well-defined meaning are malformed. The vision was always right. What's missing is the craft. Berners-Lee assumed we'd care enough about the machine-readable layer to get it right. The data says we haven't, not yet. What gives me hope is that the 36 complete files prove it's possible. They're not hard to write. They just need to be written with the same care as the human-facing content.
AI crawler policies
87.5% of the websites in our sample have no AI crawler policy in their robots.txt. No rules for GPTBot, no rules for ClaudeBot, no mention of any AI user agent at all. The web hasn't decided how to handle AI crawlers. It mostly hasn't considered the question.
Of the 12.5% that have added AI-specific rules, the overwhelming majority block rather than allow. CCBot (Common Crawl) is the most frequently blocked agent at 9.6%, followed by ClaudeBot at 8.6% and GPTBot at 8.5%.
Only 0.8% of sites explicitly allow AI crawlers. That's 11 domains out of 1,460 that have made an active, affirmative decision to let AI systems in.

These numbers paint a picture of an industry caught between two instincts: the urge to participate in AI-driven discovery, and the reflex to block what feels like uninvited scraping. Our visibility checklist walks through the technical barriers in detail. But the bigger pattern here is that most sites haven't made any decision at all. They're passively inheriting whatever defaults their CMS, hosting provider, or security plugin set for them.
The sites that have proactively set a policy tend to fall into two camps: publishers who've blocked everything out of concern about training data, and technology companies who've allowed everything because they want to be cited. There's very little in between. The nuanced approach, blocking training but allowing retrieval, using ai.txt or robots-ai.txt to set granular permissions, is almost entirely absent from the data.
Readiness tiers
We score every domain on a 0-to-5 readiness tier based on three inputs: valid AI Discovery File count, AI crawler policy in robots.txt, and Schema.org presence on the homepage. The scoring is deterministic and the full rubric is published.
The distribution is heavily bottom-weighted:
- Tier 0 (Unaware): 1.2% (18 domains). No robots.txt, no files, no signals.
- Tier 1 (Actively Blocking): 1.3% (19 domains). Have a robots.txt that blocks AI crawlers with no AI-specific files.
- Tier 2 (Passive): 76.5% (1,117 domains). Have a robots.txt but no AI-specific signals. This is where the web sits today.
- Tier 3 (Partially Ready): 19.5% (284 domains). Some combination of Schema.org, partial files, or selective crawler policies.
- Tier 4 (AI-Ready): 1.5% (22 domains). Explicit AI crawler permission, valid AI Discovery Files, and Schema.org.
- Tier 5 (AI-Optimised): 0% (0 domains). Three or more valid ADFs, explicit permission, and Schema.org. Nobody's there yet.
The average readiness score across all domains is 2.2 out of 5.0.
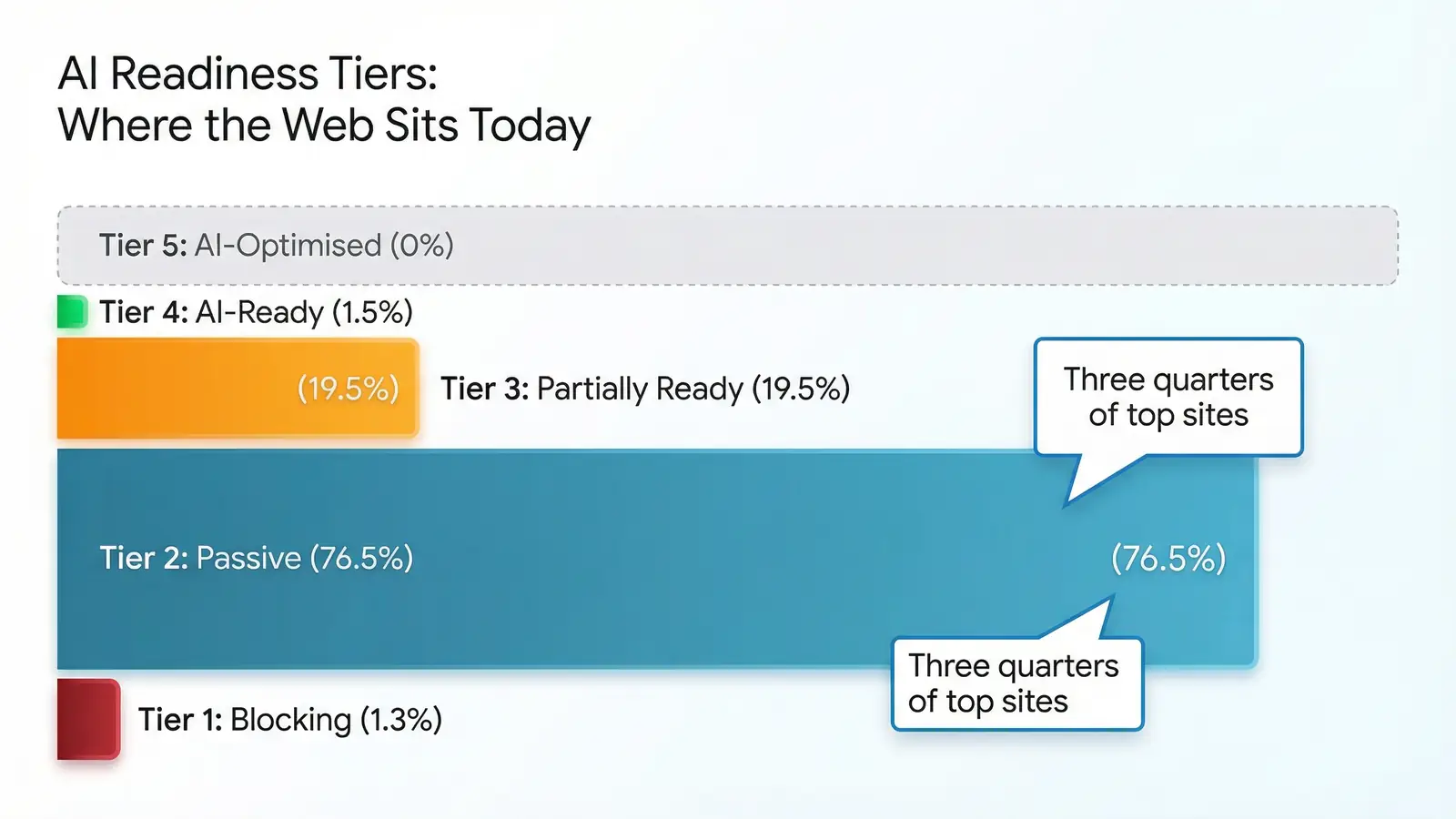
That 76.5% at Tier 2 is the number that keeps coming back to us. These aren't hostile sites. They aren't blocking AI. They just haven't done anything about it. They have a robots.txt because it's been standard practice for decades. But they've never added a single AI-specific signal. For the majority of the web, AI readiness is a non-event. Something they'll get to eventually, maybe, if someone tells them to.
How ADF compares to other web standards
One way to contextualise 6.5% adoption is to compare it against other standards that went through the same lifecycle. We checked four:
- robots.txt: 45.3% found, 43.3% valid. Proposed in 1994, it took roughly 15 years to reach majority adoption.
- ads.txt: 15.3% found, 14.7% valid. Introduced in 2017 by the IAB, adoption was driven by advertising industry requirements.
- security.txt: 12.7% found, 12.4% valid. RFC published in 2022. Adoption has grown steadily since.
- humans.txt: 2.5% found, 2.5% valid. Proposed in 2011. Never reached critical mass.
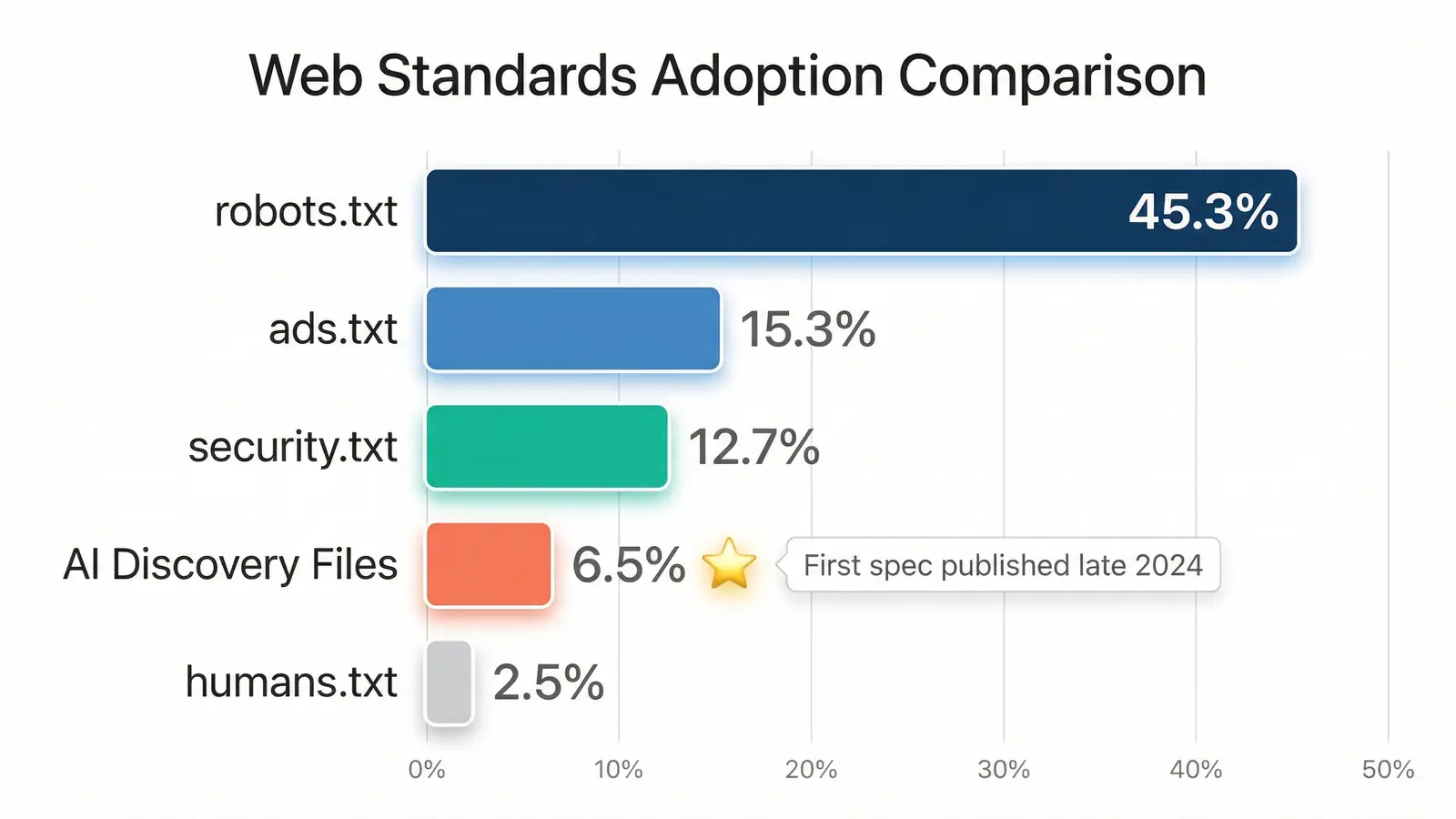
At 6.5%, AI Discovery Files have already surpassed humans.txt and are closing on security.txt. That's worth noting because ADF adoption is younger than all of these standards. The first llms.txt specification was published in late 2024. In roughly 18 months, it's achieved adoption levels that other standards took years to reach.
"AI-native docs aren't just helpful. They're now essential when you're building with tools like MCP and x402."
When we first saw Leffew's line about AI-native docs being "essential," our instinct was to push back. Essential feels strong for something with 6.5% adoption. But then we looked at the data differently. The 22 domains that reached Tier 4 aren't small players. They include Shopify, Stripe, Coinbase's own ecosystem partners, Mailchimp, SourceForge. These are companies that set infrastructure norms for their industries. When the companies building the developer tools start treating this as a requirement rather than a nice-to-have, the adoption curve doesn't follow the usual web standards trajectory. It accelerates. And that's what Leffew is really saying: for the companies that build the tools everyone else depends on, this has already crossed from optional to expected.
If security.txt's trajectory is any guide (RFC published 2022, 12.7% by early 2026), ADF adoption could reach double digits within the next two to three quarters. But only if the quality problem gets solved. A standard that reaches 15% adoption with a 56% invalidity rate isn't a success; it's a different kind of infrastructure failure. The comparison with traditional web standards tells the full story of where AI Discovery Files sit relative to these established standards.
Who is leading
The 22 Tier 4 domains aren't clustered in a single sector. They span technology, public services, recruitment, SaaS, and developer tools:
- Technology platforms: Shopify, Stripe, Opera, Netgear
- Developer infrastructure: SourceForge, Dynatrace, Optimizely
- UK public services: ScotRail, English Heritage, Energy Saving Trust, The King's Fund
- SaaS and marketing: Mailchimp, Qualtrics, OneTrust, SmartSurvey
- Recruitment and media: Reed, BM Magazine, Mainline Menswear
- Analytics and attribution: Singular, ClassLink
That cross-sector spread matters. AI readiness isn't a tech-industry concern. It's an infrastructure decision that organisations in every sector are starting to make. The fact that ScotRail and English Heritage sit alongside Stripe and Shopify tells us something important: the organisations getting this right aren't necessarily the ones with the largest engineering teams. They're the ones that recognised the shift early.
One pattern we noticed: UK public-sector organisations appear disproportionately in the Tier 4 list relative to their global ranking. English Heritage (rank 227), ScotRail (rank 957), and Energy Saving Trust (rank 489) are all in the UK top 1,000 specifically. Whether that reflects a broader trend in UK public-sector digital strategy or a few forward-thinking digital teams, the next crawl in Q2 should help clarify.
What this means for your business
Three things stand out from this data.
First, the bar is still extraordinarily low. Reaching Tier 4 today puts you ahead of 98.5% of the web's top domains. That's a competitive position that won't last. As adoption accelerates, the early-mover advantage shrinks. The window for differentiation is measured in quarters, not years. A small local business can clear that bar comfortably: see how a local removals firm scored a perfect 10/10 and ended up technically ahead of most of the Fortune 500.
Second, simply having files isn't enough. 56% of existing files are broken. If your llms.txt is a copy-pasted URL list or your ai.json has malformed syntax, you're in the same position as a site with no files at all. Worse, arguably: a broken file could actively mislead AI systems about your business. The validation and testing guide explains how to check yours.
Third, the decision not to act is itself a signal. When 87.5% of top websites have no AI crawler policy and no AI Discovery Files, AI systems are making decisions about those businesses with no guidance whatsoever. No brand rules, no permissions, no structured identity. Whatever AI says about you is whatever AI guesses about you. That's the risk. As Mark McNeece puts it in our expert Q&A: "If AI is not sure who you are, it often just leaves you out."
We publish updated crawl data quarterly. Since this first crawl, adoption has climbed each quarter: our Q3 2026 report puts it at 9.4%, with llms.txt now on 7% of sites. The full research page includes interactive charts, downloadable datasets, and methodology documentation. If you'd like to see how your site compares, the AI Visibility Checker runs the same validation checks we use in the crawl.
Check your AI readiness
The AI Visibility Checker tests your AI Discovery Files, crawler access, identity consistency, and structural readiness. Same checks we use in this research. Free, instant results.
Check your siteFrequently asked questions
What are AI Discovery Files?
AI Discovery Files are a set of machine-readable files that websites publish to help AI systems like ChatGPT, Claude, and Gemini correctly identify, interpret, and cite them. The full specification defines 10 file types, each serving a different purpose.
How many websites have AI Discovery Files?
As of Q1 2026, 6.5% of the top 1,460 websites we crawled have at least one AI Discovery File. The most common is llms.txt, found on 3.8% of sites. Adoption is growing rapidly but remains early-stage.
Why are so many AI Discovery Files invalid?
56% of the files we found failed validation. Common problems include URL dumps in place of structured content, placeholder text left over from templates, missing required fields, and incorrect file formats. Most sites that attempt an llms.txt file have never validated it against the specification.
What is an AI Readiness Tier?
AI Readiness Tiers are a 0-to-5 scoring framework used in our research methodology. They measure how prepared a website is for AI interaction based on three inputs: valid AI Discovery Files, AI crawler policy in robots.txt, and Schema.org markup. Tier 0 means no web presence signal at all; Tier 5 means fully AI-optimised.
How does AI Discovery File adoption compare to other web standards?
At 6.5%, ADF adoption has already surpassed humans.txt (2.5%) and is approaching ads.txt (15.3%) and security.txt (12.7%). For context, robots.txt took roughly 15 years to reach widespread adoption. ADF adoption appears to be on a compressed timeline, driven by the commercial urgency of AI integration.
Which websites are most AI-ready?
Only 22 domains in our sample reached Tier 4 (AI-Ready), including Shopify, Stripe, Opera, SourceForge, Mailchimp, English Heritage, and ScotRail. Zero domains reached Tier 5. Reaching Tier 4 today places a business ahead of 98.5% of top websites.
Does Google use llms.txt for AI Overviews?
Google has stated it does not currently use llms.txt for ranking in AI Overviews. However, AI Discovery Files serve a broader purpose than search ranking. They give AI systems structured business identity, permissions, and context that shapes how you're cited and represented across all AI platforms.
How can I check my website's AI readiness?
Run your domain through the AI Visibility Checker, which scans for AI Discovery Files, identity consistency, crawler access, and structural readiness. It's free and takes under a minute. You can also review the quick start guide for implementation steps.
Sources
- AI Discovery File Adoption Research, Q1 2026 - AI Visibility
- Research Methodology - AI Visibility
- The Semantic Web - Tim Berners-Lee, James Hendler, Ora Lassila, Scientific American (May 2001)
- What is llms.txt? Breaking Down the Skepticism - Mintlify
- Tranco: A Research-Oriented Top Sites Ranking
- llms.txt and AI Visibility: Results from OtterlyAI's GEO Study