
What happened, and why it matters this week
On 30 May 2026, Matt G. Southern at Search Engine Journal published "Google's I/O Demos Reveal The New Business Visibility Problem". The opening line: "Many Google I/O demos ended in transactions, bookings, or task completion. The consumer path is clear, but business visibility isn't." That's a careful sentence and it lands harder than it reads.
What Southern is describing, and what six named industry experts back up in his article, is the moment a lot of us have been waiting for and a lot of business owners haven't seen coming. Google's I/O 2026 announcements made it clear that agentic AI isn't a thought experiment anymore. The agent is going to choose which restaurant gets booked, which product goes into the cart, and which service gets called. The selection happens inside Google's stack. The business sees the outcome, or doesn't, and can't see the decision.
I've spent the last six months building a WordPress plugin and a public specification for exactly this scenario. The Search Engine Journal piece, and the named-expert reaction in it, is the first mainstream write-up I've seen that names the problem honestly without offering anything to do about it. Which is the bit worth writing.
The three demos that broke the model
Southern's article focuses on three specific Google I/O 2026 demos. Each of them puts an agent between a customer and a business in a way that breaks the assumptions traditional SEO is built on.
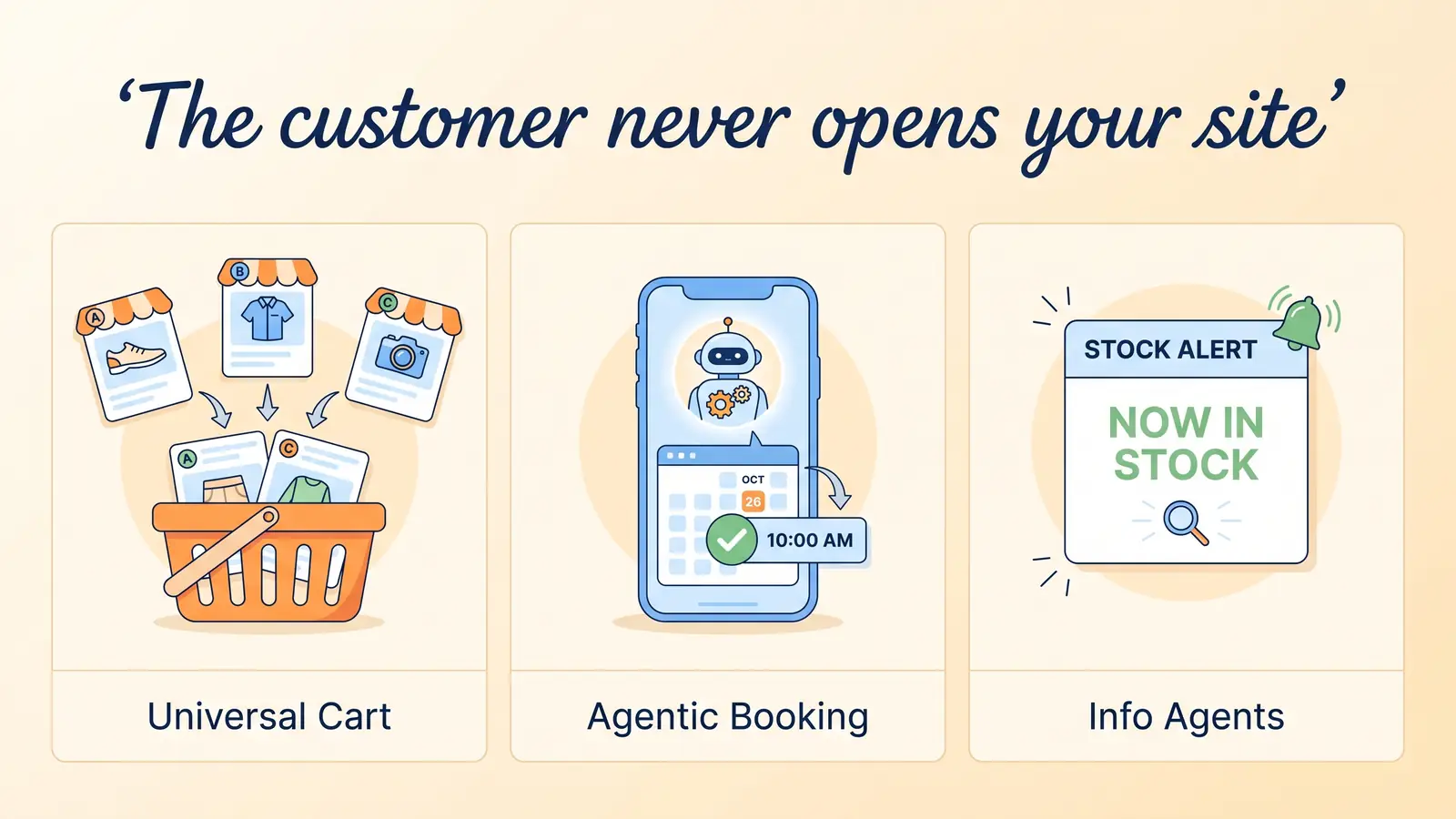
Universal Cart lets a shopper accumulate items from multiple retailers into a single Google-managed cart, across Search, Gemini, and YouTube. The shopper doesn't visit your store. They never see your homepage. The cart sees you, decides whether to include you, and checks out on your behalf. That is the demo that's been making merchants nervous, and it's the one Aleyda Solís was thinking about when she told Southern that "ecommerce SEO and AI search optimization can't be reduced to 'content around products.'"
Agentic booking goes further. The agent calls your local-services business, checks availability against your listed hours, fetches your stated pricing, books the slot, confirms with the customer, and posts the calendar invite. There is no "click to your booking page". There is no human ever landing on your site. The agent reads what you've published and acts on it. Or it doesn't, because what you've published doesn't answer its questions cleanly, and it picks the next listing.
Information agents are the quietest of the three and arguably the one with the longest tail. These are persistent background agents that monitor listings and products on behalf of a user, surfacing recommendations when something changes (a price drop, a new arrival, a relevant nearby option). They're the long-term feed into the other two. They build up an internal model of which businesses are worth considering, weeks before any transaction happens.
The thing that joins all three is what Jay Jaffin, CMO at Visor Strategic Advisors, told Southern: "Universal Cart doesn't just colonize the bottom of the funnel. It colonizes the whole thing, from the first search query to the final checkout, without your customer ever landing on your site. The adaptation window this time may be a lot shorter than a decade." That's the sentence to print out and stick on the wall.
The named experts agree, but stop short of the answer
Six named industry voices in Southern's piece all agree, in their own words, that the rules have shifted. Worth quoting in full, because every one of them lands on the same observation from a slightly different angle.
"In the future, are brands competing for clicks? Or competing to be recommended?"
Haroon Qureshi, Global Retail Experience & Partnerships Lead at WPP Media, as quoted in Search Engine Journal, 30 May 2026.
"In Google's model, merchants still own the transaction, but not the purchase intent or product discovery."
Armando Roggio, Senior Contributor at Practical Ecommerce, as quoted in Search Engine Journal, 30 May 2026.
"When Google's agent is the one calling, disorganization becomes an automatic disqualification."
Karim Al Chamaa, Founder of Implemnt, as quoted in Search Engine Journal, 30 May 2026.
The Al Chamaa line is the one that should make every operations director sit up. The agent doesn't punish you for being a small business. It punishes you for being a confusing one. If the agent can't tell, in under a second of structured data lookup, what you sell, where you operate, what your hours are, and whether your brand is the same as the other "Acme" in the next town over, you're out. Not deranked. Not penalised. Just not in the consideration set.
That's the part Southern's article identifies cleanly and then stops at. He writes: "marketers are currently building strategies based on inference rather than official guidance, and the optimization process is a matter of thoughtful guesswork." Fair. Google hasn't said anything specific about what the agents read.
What the article doesn't say, and what nobody we've seen this week is saying, is that the structured, machine-readable signals an agent needs in order to consider a business at all have already been specified, published, and are being adopted by real publishers. They aren't a Google product. They don't require permission. They're called AI Discovery Files.
What everyone is missing: the answer is already standardised
This is the bit the field is sleeping on. The selection signals an agentic shopping cart needs are exactly the things AI Discovery Files exist to standardise. The selection signals an agentic booking flow needs are also in there. The selection signals a background information agent needs are also in there. The point of the specification is that an AI agent can fetch a handful of small files at the root of your domain and learn enough about your business to put you in or out of consideration without having to crawl, render, and synthesise your whole site.
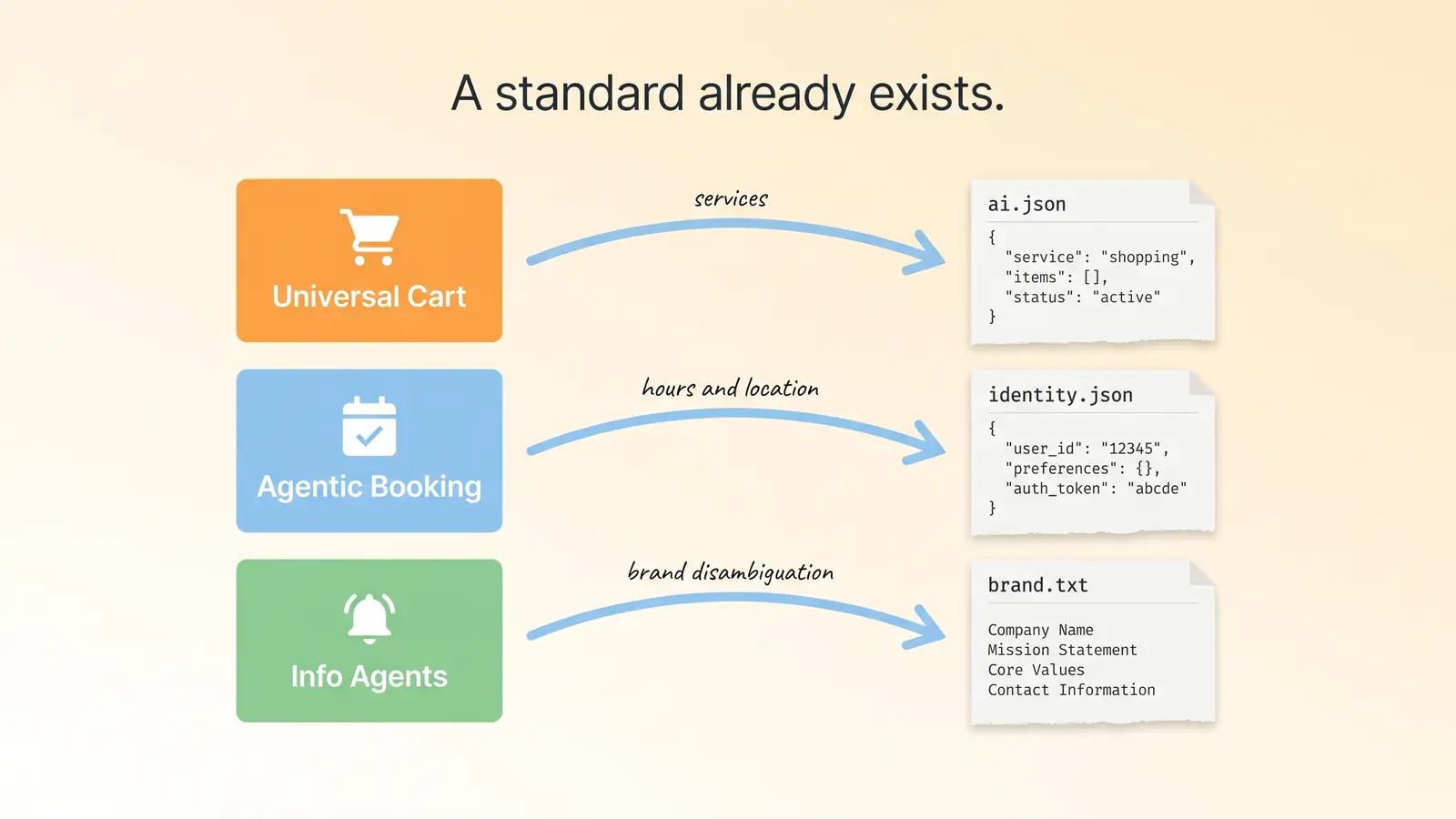
For Universal Cart and other shopping surfaces: publish ai.json (ADF-005). It's a structured JSON file that declares the services and products you actually offer, their canonical names, what they do, and where to find them on your site. It also declares the things you don't offer, which is just as important when an agent is trying to disambiguate. A clear, validated ai.json means the cart knows what to put you in for, knows what to exclude you from, and has something to attribute when a user asks "why did you pick this one?".
For agentic booking: publish identity.json (ADF-006). It's a structured JSON file declaring your legal name, trading name, location, hours, contact methods, service areas, and the canonical URLs an agent should fetch for verification. This is the file the booking agent reads to know whether you're open, whether you serve the postcode the customer is in, and whether to call you or fill in your web form. Without it, the agent has to scrape your site and guess. With it, the answer is one fetch.
For background information agents: publish llms.txt (ADF-001) and faq-ai.txt (ADF-008). The first is a curated identity statement an AI assistant can fetch to ground its model of who you are. The second is a structured Q/A file that pre-answers the common questions an agent's user might ask. Together they reduce the chance the background agent has to make something up about your brand.
And underneath all of it, brand.txt (ADF-007) for businesses whose names are confusable with competitors or with brands in other industries. The agentic stack has to disambiguate. brand.txt is how you tell it which one you are.
None of this is theoretical. NVIDIA, Dell, and ASUS already publish AI Discovery Files. We wrote it up in How AI-Ready Is the Web when we ran the first quarterly adoption crawl. Adoption is rising quarter on quarter. The spec is open. The reference implementation is the 365i AI Visibility Checker, which is free.
A worked example: Lockerfella at three weeks
If you want a concrete proof that this stuff actually moves AI assistants, the case study is already published. Lockerfella is a one-man, one-van locksmith in Brewood, Staffordshire. Launched on 8 April 2026 with all 10 AI Discovery Files in place from day one, including a hand-written llms.txt, a complete identity.json with the trading address and the service areas, and an ai.json declaring the actual services on offer (emergency call-outs, lock replacement, key cutting) and the services not on offer (commercial safes, automotive).
Nineteen days in, on 27 April, the site was the top-of-answer recommendation in both ChatGPT and Gemini for the query "brewood locksmith". Zero backlinks. No Google authority. No paid search. The full case study is in the original write-up, and the owner's follow-up interview is in AI Visibility for small businesses. That isn't agentic Universal Cart visibility specifically, because Universal Cart hasn't reached this geography yet. But it demonstrates the underlying mechanism does what we said it does. When the agent has structured, attributed, curated identity data to read, it uses it.
Universal Cart will read the same files. Agentic booking will read the same files. Info agents will read the same files. The spec was designed for this exact moment. The fact that the moment showed up at Google I/O 2026, and got a credible writeup on 30 May 2026, doesn't change what's in the spec. It just makes publishing the files more urgent.
The honest caveats nobody else is mentioning
I run the site that publishes this specification. So I'm going to put the load-bearing caveats up front, because the field doesn't need more cheerleading and Google's guide from 15 May 2026 was right to push back on hand-wave claims about machine-readable files.
Google hasn't publicly committed to consuming AI Discovery Files in its agentic stack. Anyone telling you the cart will read your ai.json is making it up. The honest position is: the file is useful to agents that already fetch it (most non-Google AI assistants do, some directly), and it's the cleanest signal available for any agent that decides to fetch it later. We expect Google's agentic stack to converge on something like this because the alternative is rendering and re-rendering the open web for every cart selection, which doesn't scale. But we can't make that promise on Google's behalf. One small straw in the wind since: Google added an Agentic Browsing category to Lighthouse in May 2026 that scores a valid llms.txt, covered in Agentic Browsing: Google now scores your site for AI agents.
Traditional schema.org and Merchant Center feeds still matter. A lot. Google's shopping surfaces have always read structured Product, Offer, and LocalBusiness schema. None of that goes away. AI Discovery Files sit alongside those and do something the existing schemas don't do, which is declare brand identity, scope, and exclusions in a way an agent can ground a recommendation on. Publish both. Schema.org tells the agent what you sell. AI Discovery Files tell the agent who you are.
An autogenerated file is worse than no file. A garbage llms.txt dumped out by a plugin and never reviewed sends the agent the wrong signal. If you can't put an editorial hour into the content, don't publish it. We wrote about this at length in What Google Actually Said About llms.txt. The same logic applies to all 10 AI Discovery Files.
What to do with your site this week
Four steps. They take a working morning if you do them properly. For the wider case on why this is now business infrastructure rather than a search tactic, see how to prepare your website for AI agents.
Step 1: audit what your domain currently looks like to an agent. Run the free AI Visibility Checker against your own site. It fetches the 10 AI Discovery Files, validates them, and reports exactly what's there and what isn't. Takes about a minute. If you've got nothing, that's the starting line. If you've got autogenerated files, that's the line in the wrong direction.
Step 2: write a real identity.json and a real ai.json by hand. Not generated. Written. The Quick Start guide walks through the minimum useful set in plain language. identity.json covers legal name, trading name, hours, location, contact, and service areas. ai.json covers what you offer and what you don't. If you read either back and can't tell what business they describe, they're not ready. They should be unambiguous, attributable, and specific.
Step 3: add the supporting files where they pull their weight. If your brand name is generic, add brand.txt. If you've got a real FAQ that an AI assistant could use to ground its answers, add faq-ai.txt. If you want a single human-readable identity statement at the root, write llms.txt from scratch. The interoperability guide handles precedence if files disagree.
Step 4: re-check, and put a re-check in the diary for next quarter. Files drift. Hours change. Service areas expand. An AI agent that fetches outdated data and recommends you for something you no longer do is worse than not being recommended at all. We re-crawl the directory we publish on a quarterly cadence for exactly this reason. Do the same on your own files.
Find out what your domain currently looks like to an agent
The free AI Visibility Checker fetches the 10 AI Discovery Files on your domain, validates them, and reports exactly what an AI agent would see. Deterministic, runs in under a minute, no sign-up, free.
Check your siteFrequently asked questions
What is the agentic visibility problem Google I/O 2026 revealed?
Google demoed three features at I/O 2026 (Universal Cart, agentic booking, and information agents) that let AI choose which businesses to recommend, which products to add to a cart, and which services to book. The business loses sight of the selection. You cannot tell whether you were considered, why you were rejected, or what would have changed the answer. Search Engine Journal's Matt G. Southern wrote it up on 30 May 2026 and called it the new business visibility problem.
How is this different from normal SEO?
Traditional SEO optimises for a human clicking a link from a search results page. In agentic search, no human clicks. An agent reads available signals about each option, picks one, and acts on the user's behalf. The new question isn't "did I rank?" but "did the agent pick me, and what signal made the choice?" That's a different problem with a different toolkit.
How do AI Discovery Files actually help?
AI Discovery Files are a set of 10 small files an agent can fetch directly from your domain to learn what you do, what you don't do, who you serve, where you operate, what your hours are, and how to disambiguate your brand. They're machine-readable, curated by you, and authoritative. When an agent has to choose between options, the option with clear, structured, attributed answers is the easier pick. The full specification covers all 10 files.
Has Google said it will use AI Discovery Files?
Not formally. Google's own AI Search Optimization Guide from 15 May 2026 says you don't need new machine-readable files to appear in its AI Search. That guidance is about Google's ranking surfaces, not its agentic surfaces, and the company hasn't spoken publicly about what its agents will consume. Other AI assistants (ChatGPT, Claude, Gemini in some configurations, Perplexity) already fetch these files when they're published, which is where the early benefit shows up.
Which file should I publish first?
Start with ai.json if you sell products or services, because Universal Cart and agentic booking both need a machine-readable services/products list. Add identity.json for hours, location, and contact, because that's what agentic booking flows need. Add brand.txt if your brand name is generic enough to be confused with a competitor. The Quick Start guide walks through the minimum useful set.
Is this a magic bullet?
No, and anyone selling it as one is wrong. Three caveats matter. First, Google's agentic stack hasn't publicly committed to consuming these files, so the win is in the non-Google AI ecosystem until that changes. Second, traditional schema.org and Merchant Center feeds still do real work in shopping surfaces, so AI Discovery Files complement them rather than replace them. Third, garbage in, garbage out: an autogenerated, un-curated file is worse than no file at all.
Has anyone shown this actually works?
A three-week-old locksmith site we built in April 2026 (Lockerfella, in Brewood, Staffordshire) launched with all 10 AI Discovery Files in place from day one. Within 19 days it was the top-of-answer recommendation in both ChatGPT and Gemini for "brewood locksmith", with zero backlinks and no Google authority. The full write-up is in our Lockerfella case study. That isn't agentic Universal Cart visibility specifically, because Universal Cart hasn't rolled out at scale yet, but it demonstrates the underlying signal does its job in the AI assistants that exist today.
What if I don't have time to write these files by hand?
Use the 365i AI Visibility Checker to see what your domain currently looks like to an AI agent, then either write a curated file yourself or commission someone who knows the spec. If you're on WordPress, the free AI Discovery Files plugin handles the file generation and includes AI-assisted import of services and FAQs from your existing site (WordPress 7.0+ with a configured AI provider). It still needs an editorial pass from a human, because no autogenerated file is as good as a curated one.
Sources
- Google's I/O Demos Reveal The New Business Visibility Problem - Matt G. Southern, Search Engine Journal (30 May 2026)
- Google Search's I/O 2026 updates: AI agents and more - Google Blog
- New ways to find your favorite sources and original content in AI Search - Google Blog (27 May 2026)
- Generative AI search optimization guide - Google Search Central (15 May 2026)
- AI Discovery Files - full specification
- ai.json specification (ADF-005)
- identity.json specification (ADF-006)
- brand.txt specification (ADF-007)
- llms.txt specification (ADF-001)
- faq-ai.txt specification (ADF-008)
- AI Discovery Files Quick Start guide
- AI Discovery Files interoperability guide
- AI Visibility - canonical definition
- Lockerfella AI Search case study
- AI Visibility for small businesses
- How AI-Ready Is the Web - Q1 2026 research
- What Google Actually Said About llms.txt
- 365i AI Visibility Checker
- AI Discovery Files plugin for WordPress (WordPress.org)
- 365i Web Design