
The headline
Three months ago, we published the first quarterly crawl of AI Discovery File adoption. The picture was bleak: most files were broken, almost nobody had an AI crawler policy, and the average readiness score sat at 2.2 out of 5.
We just ran the Q2 crawl. The direction has changed.
Adoption of AI Discovery Files rose from 6.5% to 7.2% of top websites. llms.txt, the most popular file type, grew from 3.8% to 4.9%. Valid llms.txt files jumped from 2.4% to 3.2%. Schema.org markup climbed from 25.6% to nearly 30%. And the list of AI-Ready domains now includes names you'll recognise: NVIDIA, Dell, ASUS, Datadog, and Cloudinary.
Every metric we track moved in the same direction. The web is getting more AI-ready, and the pace is picking up.
What are AI Discovery Files?
Think of AI Discovery Files as a CV for your website that only AI systems read.
When ChatGPT, Claude, or Gemini tries to answer a question about your business, it doesn't browse your website the way a person would. It looks for structured, machine-readable signals that tell it who you are, what you do, what you don't do, and how you'd like to be represented. Without those signals, AI systems guess. Sometimes they get it right. Often they don't.
AI Discovery Files solve that problem. They're a set of 10 files you publish on your website, each handling a different piece of your machine-readable identity. llms.txt gives AI a structured overview of your business. identity.json provides parseable data about your organisation. brand.txt tells AI what to call you and what not to call you. ai.txt sets your permissions for how AI can use your content.
You don't need all 10 to start. But as our data shows, the sites with the highest AI readiness scores are the ones that have moved beyond a single file. The quick start guide covers the recommended implementation order.
What we measured
On 1 April 2026, we ran the second quarterly crawl in our ADF Adoption Research programme. The crawler checked 1,995 domains drawn from the Tranco List, a research-grade domain ranking, split between the global top 1,000 and the UK top 1,000.
1,905 domains responded successfully, up from 1,460 in Q1. That improvement matters: with 445 more sites in the sample, the Q2 dataset gives us a more complete picture of what top websites are actually doing.
For each domain, we checked all 10 AI Discovery File types, validated every file against the published specification, tested robots.txt for AI crawler rules across 15 known AI user agents, and scored each domain on a 0-to-5 readiness tier. Every check is deterministic. The full methodology is published. The complete Q2 dataset is available with interactive charts and downloadable CSVs.
The growth story: Q1 vs Q2
Here are the numbers, side by side.
| Metric | Q1 2026 | Q2 2026 | Change |
|---|---|---|---|
| Sites with any ADF | 6.5% | 7.2% | +0.7pp |
| llms.txt found | 3.8% | 4.9% | +1.1pp |
| llms.txt valid | 2.4% | 3.2% | +0.8pp |
| Schema.org present | 25.6% | 29.7% | +4.1pp |
| AI-Ready (Tier 4) | 1.5% | 1.7% | +0.2pp |
| Partially Ready (Tier 3) | 19.5% | 21.7% | +2.2pp |
| Passive (Tier 2) | 76.5% | 73.7% | -2.8pp |

The percentage-point gains might look small on paper. They aren't. A 2.8 percentage-point drop in the Passive tier means hundreds of websites moved from "haven't thought about AI" to "doing something about it" in a single quarter. The Partially Ready tier absorbed most of that movement, growing from 19.5% to 21.7%.
Schema.org saw the single biggest jump: up 4.1 percentage points to 29.7%. Nearly a third of top websites now have structured data on their homepage. That's the foundation layer. When a site already has Schema.org and then adds an llms.txt, it jumps tiers quickly.
The average readiness score held at 2.2, which tells us the gains are happening at the margins rather than across the board. Most of the web is still passive. But the edge is moving, and it's moving faster than it was three months ago.
Big brands are joining
The Q1 top adopters list included names like Shopify, Stripe, and SourceForge. Impressive, but heavily weighted toward developer-focused companies. The kind of organisations you'd expect to be early adopters of a web standard.
The Q2 list tells a different story. Nine new domains entered the top 20 AI-Ready sites:
- NVIDIA (global rank 371) and Dell (rank 368): two of the world's largest technology hardware companies
- ASUS (rank 710): consumer electronics, spanning laptops to networking gear
- Datadog (rank 788) and Cloudinary (rank 725): cloud infrastructure and developer tools
- Plesk (rank 390): web hosting control panel used by millions of sites
- Greenpeace UK (rank 724) and Hobbycraft (rank 502): a charity and a retailer, neither of them tech companies
- HostGator Brazil (rank 842): hosting provider in a non-English-speaking market

That last point matters. When a Brazilian hosting company and a UK craft retailer are implementing AI Discovery Files alongside NVIDIA, this has crossed from a developer niche into broader web infrastructure. These aren't companies with dedicated AI teams. They're organisations that decided their website needed to communicate with AI systems and acted on it.
"Early adopters of llms.txt in the Fortune 500 are signaling their experimentation with generative engine optimization."
ProGEO.ai's independent research, published the day before our Q2 crawl, found that 7.4% of the Fortune 500 have implemented llms.txt. That figure landing so close to our own 7.2% across a completely different sample was a quiet validation. Two separate research programmes, different methodologies, different domain lists, and they arrived at almost the same number. The signal is real. What struck us wasn't the percentage itself, but the fact that Fortune 500 companies are now part of the conversation. Six months ago, this was a standard that developers argued about on Hacker News. Now it's showing up in enterprise web strategy.
llms.txt leads, but it's not enough
llms.txt remains the most adopted AI Discovery File by a wide margin. 93 domains serve one (4.9%), up from 55 in Q1. Of those, 61 are valid, up from 35. The file's validity ratio improved from 64% to 66%, meaning quality is keeping pace with adoption, not falling behind it.
llms.html comes second at 47 domains found, but the quality picture is still poor: only 10 are valid. Most are generic HTML pages that happen to live at the /llms.html path.
Beyond those two, adoption remains near zero:
- ai.txt and ai.json: 2 found each, none valid
- brand.txt and faq-ai.txt: 1 found each (new in Q2, both invalid)
- robots-ai.txt: 1 found, 1 valid
- identity.json and developer-ai.txt: 0 found

The tiny appearances of brand.txt and faq-ai.txt are new. They didn't exist in our Q1 data at all. That's not a trend yet, but it's a pulse.
"Site authors know best, and can provide a list of content that an LLM should use."
Howard wrote that when he proposed the llms.txt standard in 2024. At the time, it felt like an optimistic starting point: give site owners a way to curate what AI systems see. Now, eighteen months in, the data shows both the promise and the limitation of that idea. Sites are providing the list. But a list isn't enough.
An llms.txt tells AI systems who you are in broad strokes. It can't control what they call you, clarify your service boundaries, or set permissions for how your content gets used. That's what the supporting files do. A brand.txt tells AI what to call you and what not to call you. An identity.json provides structured data AI systems can parse without interpretation. An ai.txt sets your terms for AI use. Without them, AI systems fill in the gaps with whatever they infer from your website, and inference is a polite word for guessing.
The data makes this visible. The 33 domains that reached Tier 4 (AI-Ready) all combine a valid llms.txt with explicit crawler permissions and Schema.org markup. Zero domains have reached Tier 5, which requires three or more valid AI Discovery Files. The ceiling for a single file is Tier 4, and reaching it still puts you ahead of 98.3% of top websites. But the next step requires going beyond the one file everyone's heard of.
The web is making deliberate AI choices
One of the quieter findings in the Q2 data is the shift in AI crawler policies.
In Q1, 87.5% of sites had no AI crawler policy in their robots.txt. No rules for GPTBot, no rules for ClaudeBot, nothing. By Q2, that dropped to 85%. Still overwhelmingly passive, but the direction is clear: more organisations are actively deciding how AI crawlers interact with their content.
Selective blocking rose from 10.3% to 12.3%. Sites explicitly allowing AI crawlers grew from 0.8% to 1.2%. Both numbers are small, but both are moving. GPTBot and ClaudeBot are now each blocked by 10% of sites in our sample, up from around 8.5% in Q1. CCBot (Common Crawl) leads blocking at 10.6%.
The pattern we're watching is the shrinking middle. 85% of sites still have no policy. But every quarter, a slice of that passive majority moves into one of the active categories: blocking, allowing, or setting selective permissions. The question isn't whether to have a policy; it's that most websites haven't realised they need one. Our robots-ai.txt specification offers a structured way to set granular AI permissions beyond what robots.txt allows.
Where ADF sits among web standards
Comparing AI Discovery Files against established web standards gives the growth some context:
- robots.txt: 52.1% found, 50.3% valid. The thirty-year-old standard remains the foundation.
- ads.txt: 16.7% found, 16.2% valid. Introduced in 2017, driven by advertising industry mandates.
- security.txt: 14.3% found, 14% valid. RFC published in 2022. Steady growth since.
- AI Discovery Files: 7.2% with any file. llms.txt specifically at 4.9%.
- humans.txt: 2.5% found, 2.5% valid. Proposed in 2011. Never reached critical mass.
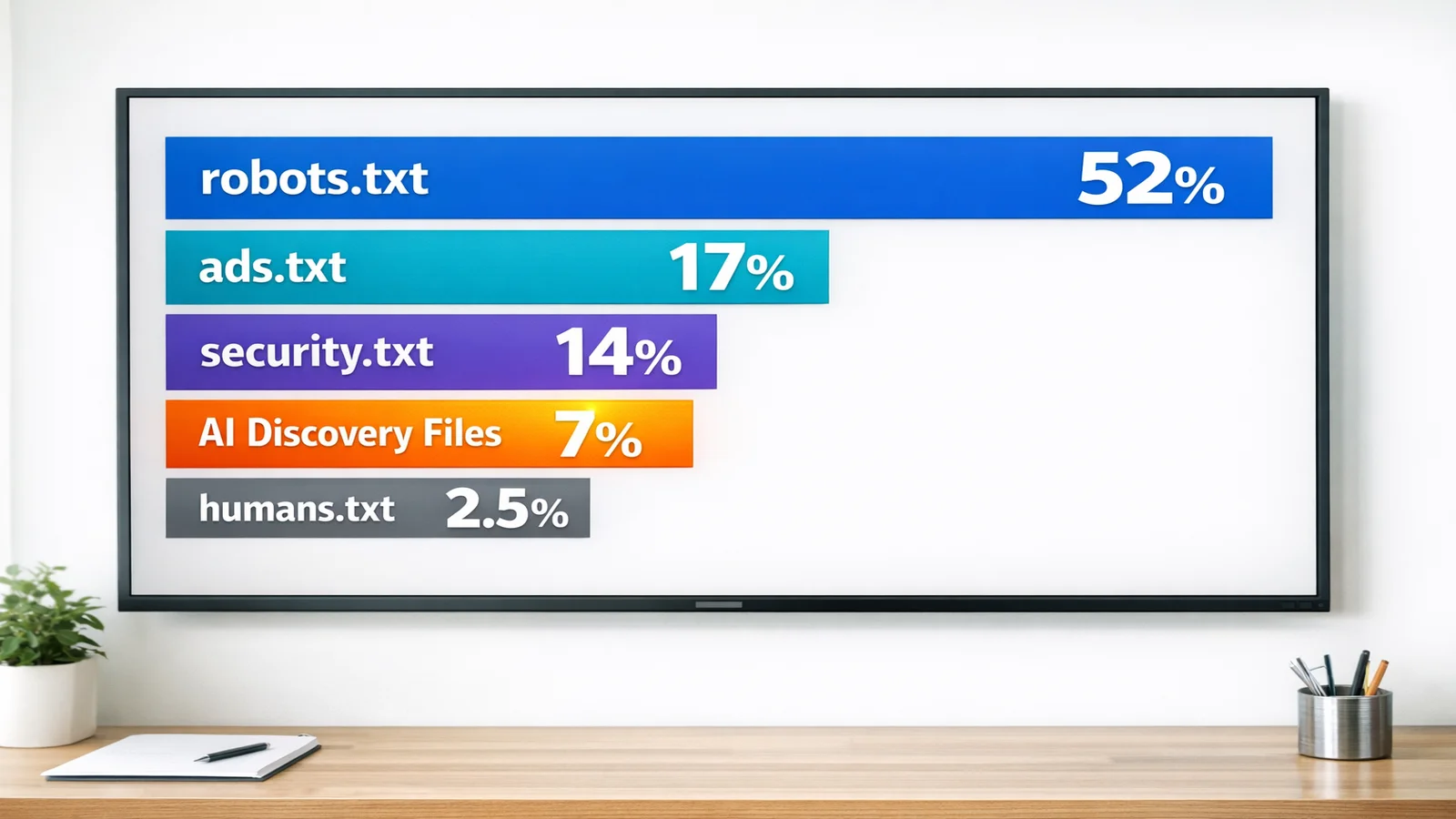
ADF has already passed humans.txt and is closing on security.txt. For a standard that originated in late 2024, reaching 7.2% in eighteen months is fast. The full comparison with traditional web standards puts this trajectory in historical perspective.
What's different about ADF adoption is the driver. robots.txt grew because search engines needed it. ads.txt grew because the advertising industry mandated it. security.txt grew because security researchers pushed for it. AI Discovery Files are growing because businesses are realising that AI systems are already talking about them, and they want a say in what gets said. Our expert Q&A on AI Visibility explores this shift in detail.
That's a commercial driver, not a technical mandate. And commercial drivers tend to accelerate faster once they cross a visibility threshold. Vercel reports that ChatGPT now refers around 10% of their new signups, up from 1% just six months earlier. When AI referrals start showing up in analytics dashboards, the conversation about AI readiness moves from "should we?" to "why haven't we?".
What this means for your website
The bar is still very low. 7.2% of top websites have any AI Discovery File. Reaching Tier 4 (AI-Ready) puts you ahead of 98.3% of the web's most prominent domains. That's an absurd competitive position for something that takes a few hours to implement. But it won't last. The quarter-over-quarter trend shows the Passive tier shrinking and every active tier growing.
One file isn't the finish line. llms.txt gets you started. It's the file AI systems look for first, and it's where 93 of the 137 adopting sites have focused. But zero sites in our sample have reached Tier 5, which requires three or more valid files. identity.json, brand.txt, and ai.txt each handle a part of your machine-readable identity that llms.txt can't. The quick start guide maps out the recommended order.
Doing nothing is a choice AI systems will make for you. When 85% of top websites have no AI crawler policy and no AI Discovery Files, AI systems represent those businesses with no guidance at all. No brand rules, no permissions, no structured identity. Whatever ChatGPT says about your business is whatever it infers from what it can find. That's the risk. The businesses in our Tier 4 list have decided they'd rather control the narrative than leave it to inference.
We publish updated crawl data every quarter, with the next crawl scheduled for Q3 2026. The full research page includes trend charts, quarterly reports, and downloadable datasets. If you want to see where your site stands right now, the AI Visibility Checker runs the same validation we use in the crawl.
See where your website stands
The AI Visibility Checker scans for all 10 AI Discovery Files, checks your AI crawler permissions, and scores your readiness. Same checks we use in this research. Free, instant results.
Check your site nowFrequently asked questions
What are AI Discovery Files?
AI Discovery Files are machine-readable files you add to your website so AI systems like ChatGPT, Claude, and Gemini can accurately identify your business, understand what you do, and cite you correctly. The specification defines 10 file types, each serving a different purpose.
How many websites have AI Discovery Files in 2026?
As of Q2 2026, 7.2% of the top 1,905 websites we crawled have at least one AI Discovery File, up from 6.5% in Q1. Independent research from ProGEO.ai found a similar figure: 7.4% of the Fortune 500 have implemented llms.txt.
Which AI Discovery File should I create first?
Start with llms.txt. It's the most widely adopted file (4.9% of top sites) and gives AI systems a structured overview of your business. Our step-by-step guide walks through creating one in under 30 minutes. After that, add identity.json and brand.txt to lock down your structured identity.
Does llms.txt actually work?
Vercel reports that ChatGPT now refers around 10% of their new signups, up from 1% six months earlier. They attribute this partly to generative engine optimisation efforts including llms.txt. Our data shows that the sites reaching the highest AI readiness tiers all have valid llms.txt files combined with supporting files and clear crawler permissions.
Why do I need more than just llms.txt?
A single llms.txt tells AI systems who you are in broad strokes, but it can't carry your full machine-readable identity. brand.txt controls what AI calls you (and what it shouldn't). identity.json provides structured data AI systems can parse without guessing. ai.txt sets your permissions for AI use. Together, they remove ambiguity.
Is Google using AI Discovery Files for AI Overviews?
Google hasn't confirmed it uses llms.txt for AI Overviews. But AI Discovery Files serve a broader purpose than any single platform. They give every AI system, from ChatGPT to Perplexity to Claude, the structured signals they need to represent your business accurately. Waiting for Google to announce support means falling behind the sites already visible to every other AI platform.
How can I check if my website is AI-ready?
Run your domain through the AI Visibility Checker. It scans for all 10 AI Discovery File types, checks your AI crawler permissions, validates identity consistency, and scores your structural readiness. It's the same validation we use in this research. Free, instant results.
Sources
- AI Discovery File Adoption Research, Q2 2026 - AI Visibility
- AI Discovery File Adoption Research, Q1 2026 - AI Visibility
- Research Methodology - AI Visibility
- ProGEO.ai research finds 7.4% of the Fortune 500 have implemented llms.txt - GlobeNewsWire (March 2026)
- /llms.txt — a proposal to provide information to help LLMs use websites - Answer.AI (September 2024)
- How Vercel's adapting SEO for LLMs and AI search - Vercel
- Tranco: A Research-Oriented Top Sites Ranking